ここでは、物体の検出についてFaster R-CNN、YOLO、SSDのようなさまざまなアルゴリズムについて説明します。 物体検出の最先端、各手法の直感、アプローチ、それぞれの特徴を見ていきます。
(ドラフト状態なので、随時修正と加筆する予定です。)
1. 物体検出とは
物体検出は画像を取り込み、画像の中から定められた物体の位置とカテゴリー(クラス)を検出することを指します。
犬猫分類器を作成したとき、猫や犬の画像を撮り、そのクラスを予測しました。
図1−1

猫と犬の両方が画像に存在する場合、どう処理すべきでしょうか。
図1-2

この場合、モデルは何を予測するのでしょうか?
この問題を解決するために、両方のクラス(犬と猫)を予測する複数ラベル分類子を訓練することが可能です。
しかし、私たちはまだ猫や犬の位置を知りません。 画像内のクラスが与えられた物体の位置を特定する問題は、localization と呼ばれます。 物体クラスがわからない場合は、位置を決定するだけでなく、各物体のクラスを予測する必要があります。
図1-3
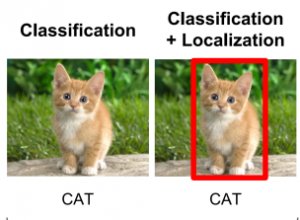
クラスと一緒に物体の位置を予測することを物体検出(object detection)と呼びます。
画像から物体のクラスを予測する代わりに、クラスとその物体を含む矩形(バウンディングボックスという)を予測する必要があります。
矩形を一意に識別するには4つの変数が必要です。 したがって、イメージ内の物体の各インスタンスについて、次の変数を予測します。
- class_name
- bounding_box_top_left_x_coordinate
- bounding_box_top_left_y_coordinate
- bounding_box_width
- bounding_box_height
複数種類の物体を1つの画像で検出すると、マルチクラスの物体検出の問題が発生する可能性があります。
図1-4

次章ではまず、物体検出器を訓練する一般論を見ていきます。
歴史的に、2001年にViolaとJonesによって提案されたHaarカスケードから始まる物体検出には、多くのアプローチがありました。しかしここでは、ニューラルネットワークとDeep Learningを使用する最先端の方法にフォーカスしたいと思います。
物体検出は、
1. 入力画像から固定サイズのウィンドウをすべての可能な位置で取得して、
2. これらのパッチ(領域)を画像分類器に入力する
という分類問題としてモデル化されます。
図1-5

各ウィンドウは、ウィンドウ内の物体のクラス(または存在しない場合はバックグラウンド)を
予測する分類器に渡されます。それにより、画像内の物体のクラスと位置の両方がわかります。 シンプルですが、果たしてどのようにしてウィンドウサイズを知ることが出来るのでしょうか?
次のサンプルでは1枚目は小さなサイズであり、2枚目は大きなサイズです。
図1-6

図1-7

物体は様々なサイズにすることができます。 この問題を解決するため、元の画像を複数サイズにサイズ変更した画像を用意します。これらの画像のいずれかで、選択したサイズのウィンドウ内に物体が完全に含まれることになります。
一般的には、特定の条件(典型的には最小サイズに達する)が得られるまで、画像はダウンサンプリング(サイズが縮小)されます。 これらの画像のそれぞれについて、固定サイズのウィンドウ検出が実行されます。
このようなピラミッドには64レベルまでのレベルがあるのが一般的です。 これらのウィンドウは全て、関心のあるオブジェクトを検出するために分類器に入力され、サイズと場所の問題を解決します。
図1-8

もう1つ、縦横比(アスペクト比、aspect ratio)の問題があります。 座っている人が立っている人や眠っている人とは異なるアスペクト比を持つように、多くの物体がさまざまな形で存在します。アスペクト比については後述します。
R-CNN、Faster R-CNN、SSDなどのような物体検出のためのさまざまな方法があります。それぞれの特徴を見ていきます。
2. 物体検出の様々なアルゴリズム
2-1. HOG機能を使用した物体検出
Navneet DalalとBill Triggsは、コンピュータビジョンの歴史の画期的な論文で、2005年にHOG(Histogram of Oriented Gradients)機能を導入しました。Hog機能は計算コストが安く、多くの現実世界の問題に適しています。
スライディングによって得られた各ウィンドウ上で、我々は分類器を作成するためにSVM(サポートベクターマシン)に供給されるHog Featureを計算します。歩行者検出、顔検出、その他の多くの物体検出ユースケースのビデオでこれをリアルタイムで実行することができました。
2−2. R-CNN (Region-based CNN)
物体検出のタスクに対してもCNNのアルゴリズムを上手く応用できないか?という課題を解く先駆けとなった論文[3]です。
深層学習の登場後、物体検出はより正確な畳み込みニューラルネットワークに基づく分類器に置き換えられました。しかし、CNNは非常に遅く、計算上非常に高価で、スライディングウィンドウ検出器によって生成された非常に多くのパッチでCNNを実行することは不可能でした。
R-CNNは、Selective Searchと呼ばれる物体候補(object proposal)アルゴリズムを使用することでこの問題を解決しました。
R-CNNの目的は、画像を取り込み、画像内の主要な物体を bounding box を介して、正確に特定することです。
- 入力:画像
- 出力:画像内の各物体の境界ボックス+ラベル
しかし、これらの bounding box がどこにあるのかをどのように見つけ出すのでしょうか?
R-CNNは 画像の中にたくさんのボックスの候補をリストアップし(region proposal)、 それらのどれかが実際に物体に対応しているかどうかを調べます。
図2-2-1

Selective Search(上記の画像参照) では、
- 複数のスケールのウィンドウを調べて、
- テクスチャ、色、または強度を共有する隣接ピクセルを探し
物体を識別します。
図2-2-2
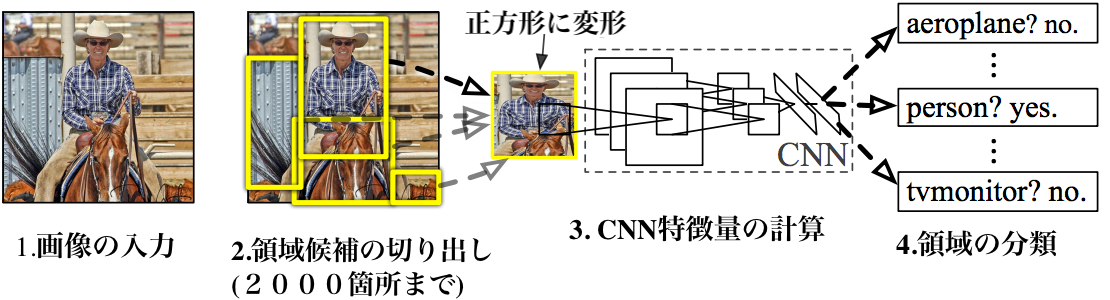
CNNの全結合層は固定サイズの入力を受け取るので、生成されたすべてのボックスを固定サイズ(VGGの場合は224×224)にサイズ変更しCNN部分に渡します。
R-CNNのアルゴリズムは、以下の流れになります。
- 物体らしさ(Objectness)を見つける既存手法(Selective Search)を用いて、画像から領域候補(Region Proposals)を探します(2000個程度)
- 領域候補の領域画像を 全て一定の大きさにリサイズして CNNにかけて特徴量を取り出す
- 取り出した特徴量を使って複数のSVMによって学習しカテゴリ識別、regressorによってBounding Box の正確な位置を推定
図2-2-3

このアルゴリズムにより、PASCAL VOC 2012のデータセットにおいて(Deepじゃない)既存手法の精度を30%以上改善し、53.3%のmAPを達成しました。
non-maximum suppression
IoU(Intersection over Union)値とは、画像の重なりの割合を表す値であり、
この値が大きいほど画像が重なっている状態ということになります。
逆に、小さいほど重なっていない状態ということになります。例えば、IoU=0のときは全く重なっていない状態ということになります。
non-maximum suppressionは、このIoUを利用して、同じクラスとして認識された重なっている状態の領域を抑制するためのアルゴリズムです。
IoU値の閾値を0.3という具合に定め、この閾値よりも大きいものを重複した物体領域の候補として外し、閾値に満たないものは、物体領域の候補として残すことになります。
R-CNN の欠点
この手法の欠点としては下記のものが挙げられます。
- 学習を各目的ごとに別々に学習する必要がある: CNNのFine-tune / 複数のSVMによるクラス分類 (Classification) /物体の詳細位置推定 (Bounding Box Regression)
- 実行時間がすごく遅い:GPUを使って10-45 s/image
2-3. SPP-net(spatial pyramid pooling)
Selective Search によって生成された2000の領域候補(region proposal)上でCNNを実行すると、多くの時間がかかる問題がありました。SPP-Net はこの改善を試みたもので、画像1枚から一回のCNNで大きな特徴マップを作成した後、領域候補の特徴をSPPによってベクトル化し、スピードはGPU上にて24-102倍に高速化を実現しました。
(2000個の領域候補はかなり領域の重複が多いため、重複する画像領域をCNNで特徴抽出するのはかなり無駄です。)
その領域に対応する最後の畳み込み層の特徴マップのその部分だけにプーリング操作を実行することで実現しています。
中間層で起こるダウンサンプリング(VGGの場合は座標を単に16で割る)を考慮に入れて、畳み込み層上の領域を投影することによって、領域に対応する畳み込み層の矩形部分は計算可能です。
空間プーリング
R-CNNでは、固定サイズの画像を入力として識別していました。
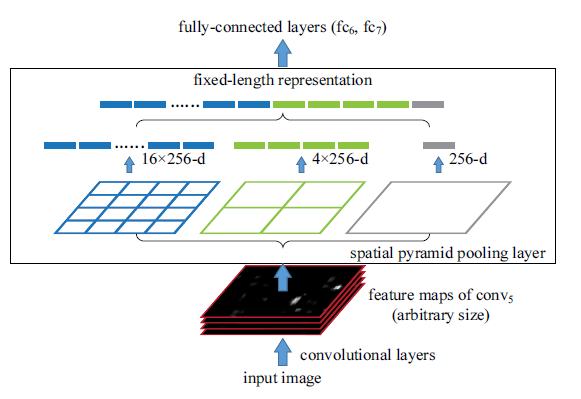
SPPnetでは、Spatial Pyramid Pooling (SPP)という手法を用いることで、 CNNで畳み込んだ最終層の特徴マップを縦横可変サイズで取り扱えるようにしました。
SPPは伝統的に使用されているmax-pooling とは対照的に、最後の畳み込みレイヤの後に空間的なプーリングを使用します。SPP層は、任意のサイズの領域を一定数のビンに分割し、各ビンに対して max-pooling を実行します。
ビンの数は同じであるため、下の図に示すように、一定のサイズのベクトルが生成されます。
図2-3
SPPの欠点
この手法の欠点としては下記のものが挙げられます。
- 学習がad hocなのは変わらず
- 最終的な学習時にSPP Layer以下のパラメータが更新できない
2-4. Fast R-CNN
- RoI pooling layerという、SPPのpyramid構造を取り除いたシンプルな幅可変poolingを行う
- classification/bounding box regressionを同時に学習させるための multi-task loss によって1回で学習ができるようにする(ad hocでない)
- オンラインで教師データを生成する工夫
- multi-task lossの導入により、Back Propagationが全層に適用できるようになったため、全ての層の学習が可能に。
- 実行速度は、VGG16を用いたR-CNNより9倍の学習速度、213倍の識別速度で、 SPPnetの3倍の学習速度、10倍の識別速度を達成。
<Fast R-CNN の改善点>
1 : RoI (Region of Interest) プーリング
関心領域プーリング、又はRoIプーリングは畳み込みニューラルネットワークを使用する物体検出タスクで広く使用される操作です。その目的は、不均一なサイズの入力に対して最大プールを実行して、固定サイズの特徴マップ(たとえば7×7)を得ることです。2015年4月にRoss Girshickによって最初に提案されています。([3])
オープンソースのRoIプーリング実装例
https://github.com/deepsense-ai/roi-pooling
画像の多くの領域候補が必ず重複し、同じCNN計算を何度も(最大2000回)実行していました。なので、画像を一回のみCNN実行し、領域間で計算結果を共有しようと試みました。
CNNの特徴マップから対応する領域を選択することによって、各領域のCNN特徴がどのように取得されるかを確認します。次に各領域の特徴がプーリングされます(通常 max poolingを使用します)。したがって、従来手法の最大2000回とは対照的に、元の画像の1回のパスのみCNNが実行されます。
2:すべてのモデルを1つのネットワークに統合
図2-4−1
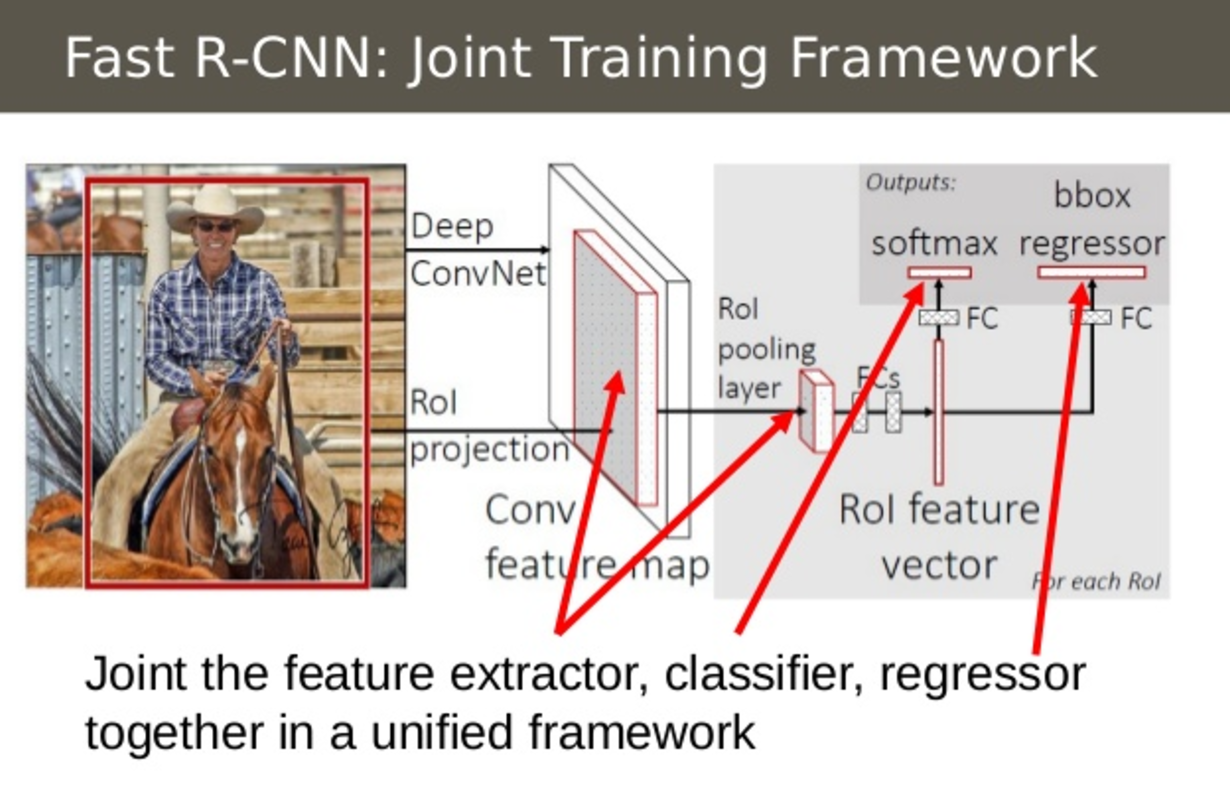
Fast R-CNNの二つ目の改善点は、CNN、分類器(classifier)、バウンディングボックス回帰子(regressor)を単一のモデルで統合してトレーニングすることです。即ち、エンドツーエンド(※1)のトレーニングが可能という点です。
フレームワークの最初の段階で、画像の特徴を抽出し(CNN)、分類し(SVM)、より正確なバウンディングボックスの位置の回帰子(regressor)と異なるモデルを使用し、Fast R-CNNでは単一のネットワークを使用して3種類の計算をします。SVM分類器をCNN上のsoftmax層で置き換えて分類を出力します。また、bounding box 座標を出力するためにsoftmax層に平行な線形回帰層を追加しています。
※1 End-to-end 学習
前処理かけたり複数のモデルを組み合わせたりすることなく、入力と出力の関係を直接単一のモデルで学習すること
- この変更により、SPPネットと比較してトレーニング時間全体を短縮し、精度を向上させます。
- Fast R-CNN では bounding box の走査に Selective Search を利用していることは変わらず。
全体モデルへの入力と出力は次のとおり。
- 入力:領域候補生成済みの画像情報。
- 出力:各領域の物体分類と bounding box 座標とサイズ
RoIプーリングの詳細
RoIプーリングは実際に何をするのかを見ていきます。
入力リストからすべての関心領域について、それに対応する入力特徴マップのセクションを取り、それを予め定義されたサイズ(例えば、7×7)にスケールします。スケーリングは次の方法で行います。
- 領域候補を同じサイズのセクションに分割します(その数は出力の次元と同じ)
- 各セクションで最大値を見つける
- これらの最大値を出力バッファにコピーする
その結果、サイズの異なる長方形のリストから、固定サイズの対応する特徴マップのリストをすばやく取得できます。RoIプーリング出力の次元は、実際には入力特徴マップのサイズや領域提案のサイズに依存しないことに注意。領域候補を分割するセクションの数だけによって決定されます。
RoIプーリングのメリットの1つは処理速度です。フレームに複数の物体候補がある場合(通常はたくさんある)、それらのすべてに対して同じ入力特徴マップを使用できます。ネットワーク処理の初期段階での畳み込み計算は非常にコストがかかるので、このアプローチは時間を大幅に節約できます。
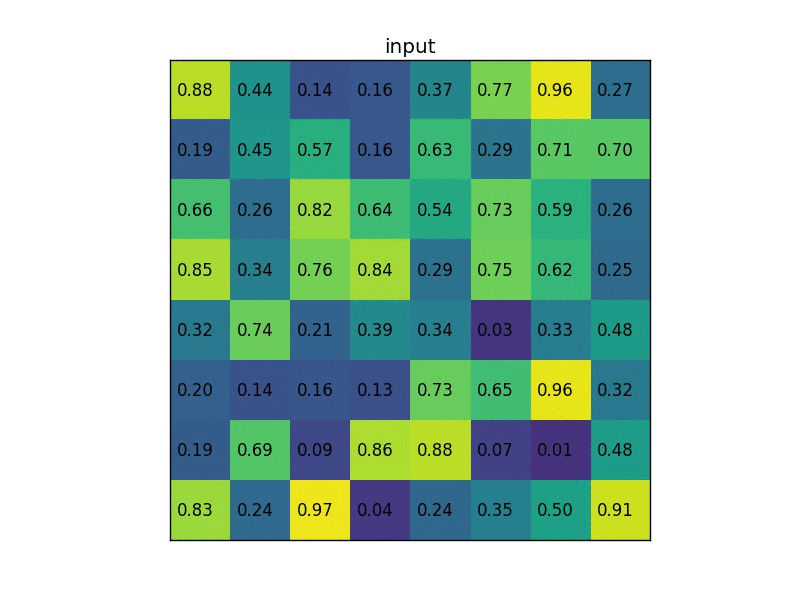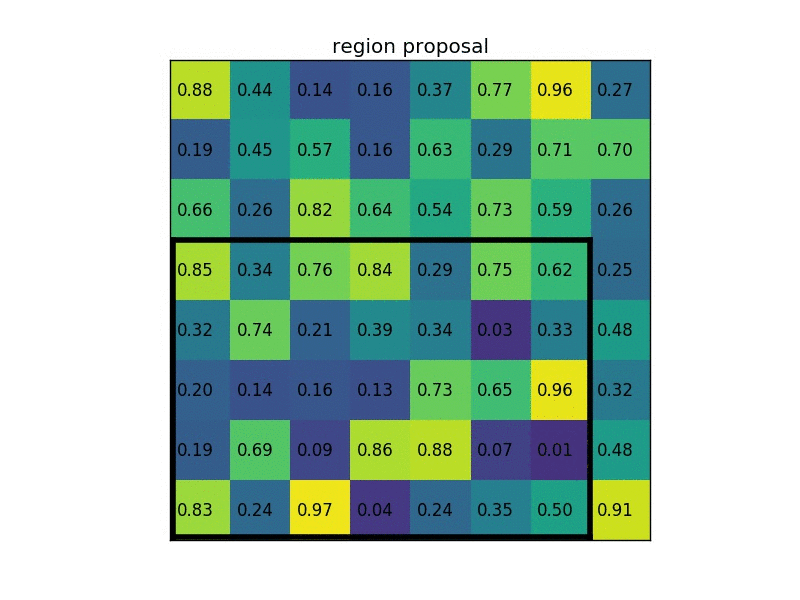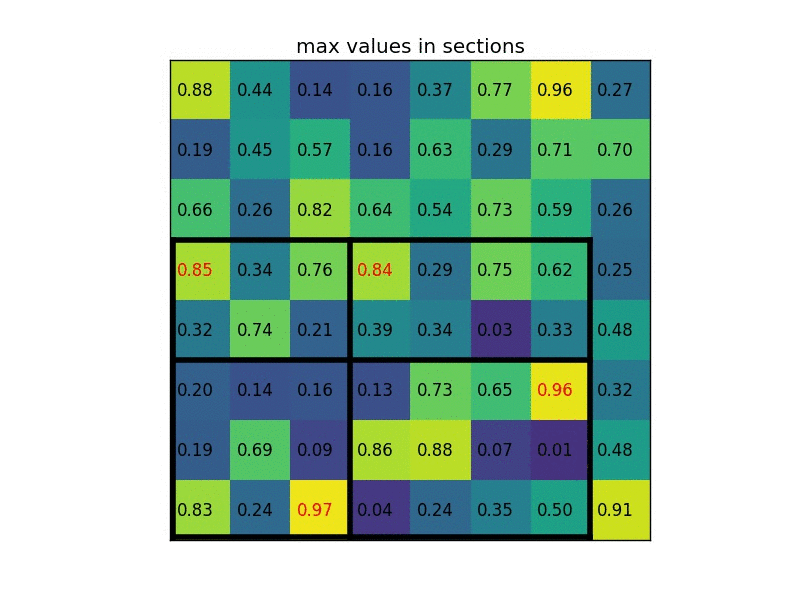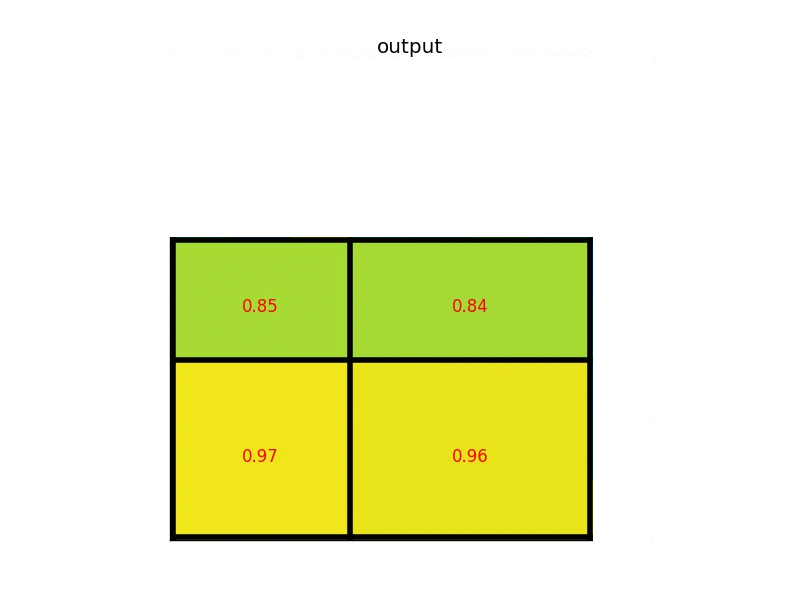
実際の動作を見てみましょう。今、8×8の単一の特徴マップの1つの関心領域に対して2×2の出力サイズでRoIプーリングを実行してみます。入力特徴マップは次のようになります。
図2-4−2
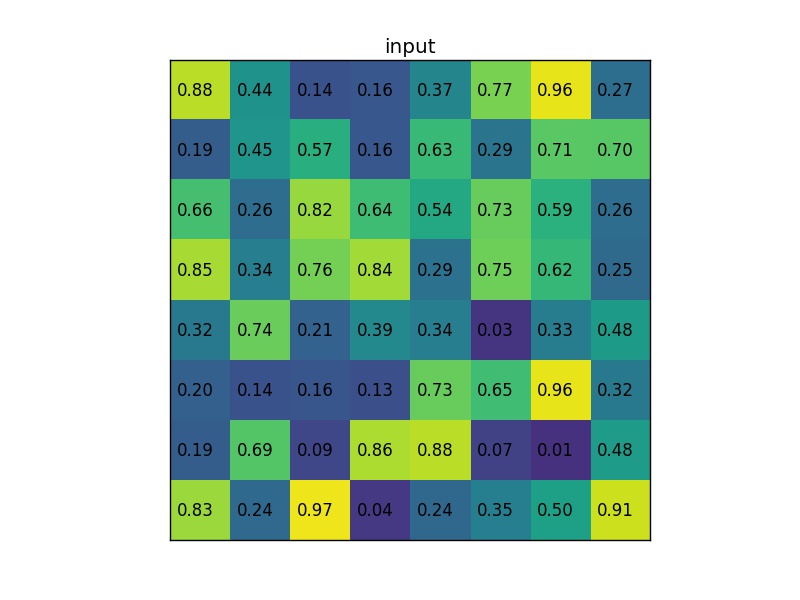
領域候補(左上、右下座標)の情報(0、3)、(7,8)があるとします。
図2-4−3
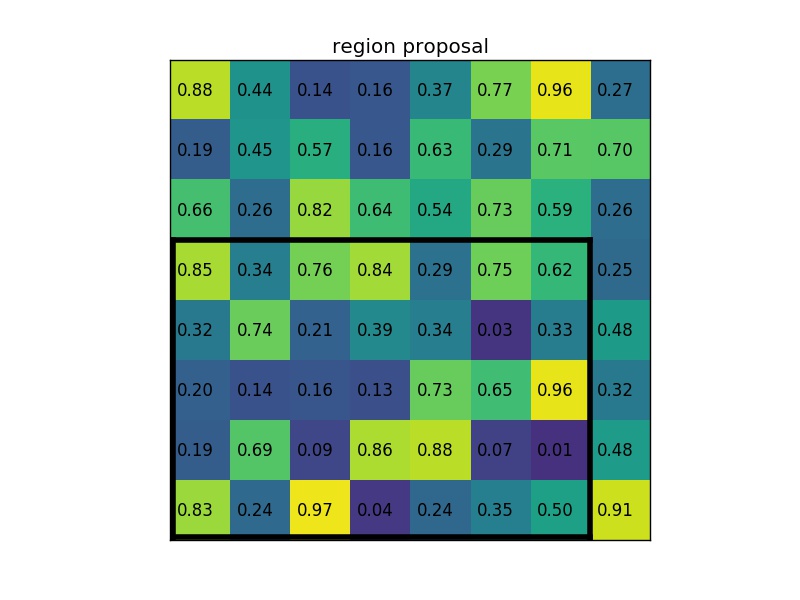
通常は、それぞれに複数の特徴マップと複数の候補がありますが、この例では単純化しています。出力サイズが2×2であるため、(2×2)セクションに分割すると、次のようになります。
図2-4−4
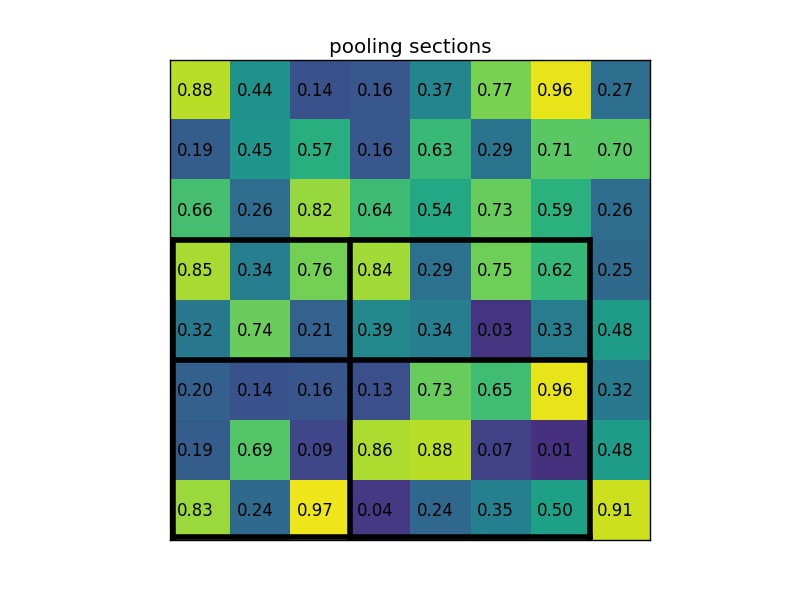
関心領域のサイズは、プールセクションの数によって完全に割り切れる必要はないことに注意。
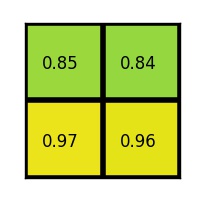
この場合、RoIは7×5で、プールセクションは2×2です。各セクションの最大値は次のとおりです。
図2-4−5
アニメーションの形で提示された例を示しておきます。
図2-4−6
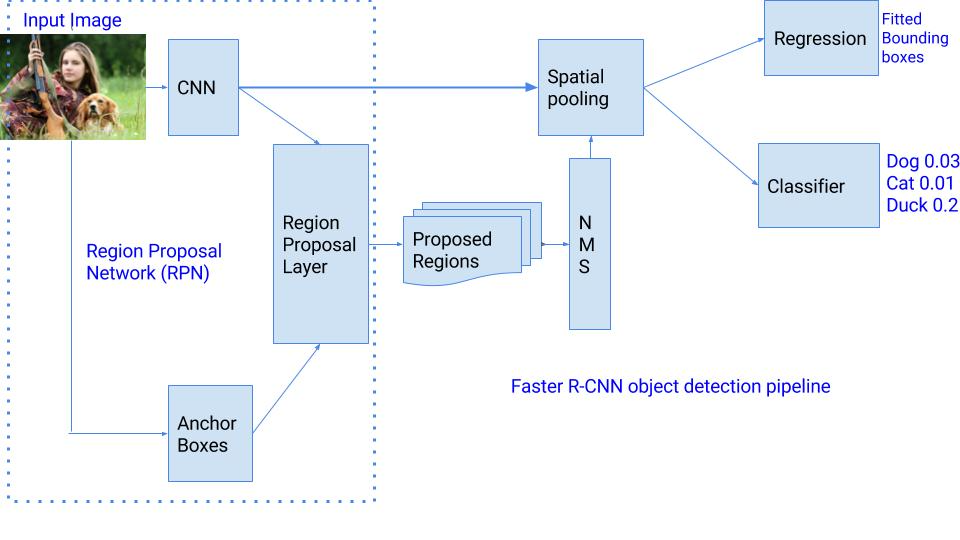
2-5. Faster R-CNN
ネットワーク概要
ネットワークを大別すると、backend部、RPN部、head部に分かれます。
backend部は、入力画像の特徴を抽出する役割を担います。論文中では VGGとResNetを採用しています。
RPN部は「物体らしき領域候補」が抽出されます。
head部は「物体らしい」と判定された領域について、RoIプーリングを利用して物体のクラスの確率と領域位置を推定します。
RPN(Region Proposal Network)の導入
Fast R-CNN のネットワーク全体のボトルネックは、Selective Search を利用した領域候補の生成部分でした。
Faster R-CNN では、ROI(region of interest)の生成のために、Selective Searchを RPN(Region Proposal Network) と言われる小さな畳み込みネットワークに入れ替えました。RPNへ渡す特徴マップの生成前に一度だけCNNを実行します。
図2-5-1
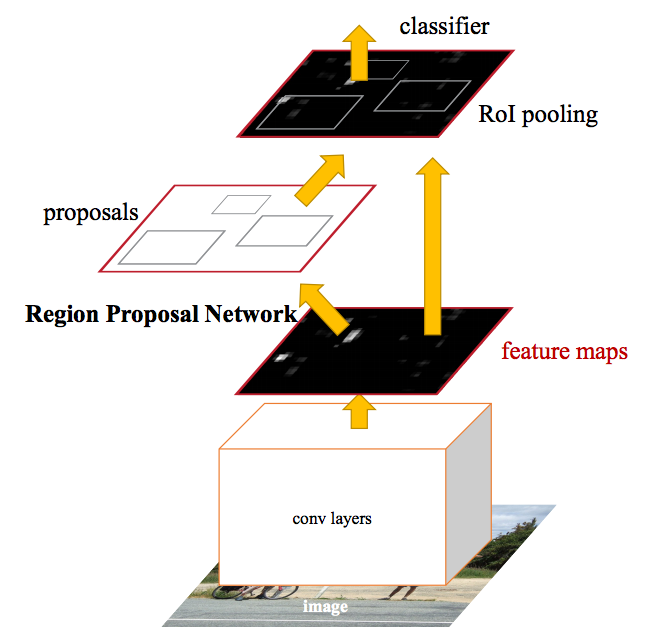
図2-5-2
アンカーボックスの導入
画像内の物体は特定の一般的なアスペクト比とサイズに調整が必要となります。
図2-5-3

例えば、上図のように、人なら人の形に似た縦長の長方形の箱が必要です。このようにして、アンカーボックスと呼ばれ、k個のアスペクト比をもつボックスを作成します。一つのアンカーボックスごとに、画像内の位置ごとのバウンディングボックスとスコアを出力します。
それぞれの位置で、
- スケール128×128, 256×256, 512×512の3種類のアンカーボックスを使用します。
- 同様に、アスペクト比では、1:1, 2:1, 1:2 の3つのアスペクト比を使用します。
→したがって、各場所で合計で9個(3×3)のアンカーボックスを保持します。
図2-5-4
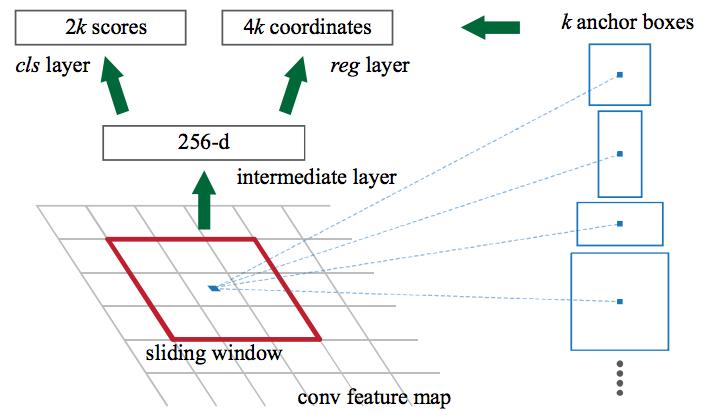
図2-5-1で、アンカーボックスはRPNがバックグラウンドなのかフォアグラウンドなのか、即ち物体でないのか、物体なのかの確率を予測します。
上図で示すように、アンカーボックス一つにつきアスペクト比が k 個分用意され、それぞれが物体か背景かで2値分類のため、分類器に渡って、2k個のスコアを算出します。また、アンカーボックスの座標(x,y)とサイズ(高さ、幅)の4つの情報を、正確なバウンディングボックス回帰子(regressor)で 4k の値を予測します。
Region Proposal Network への入力と出力は次のとおり。
- 入力: CNN 特徴マップ
- 出力: アンカーごとの bounding boxと物体か否かの2値スコア
各領域のアンカーボックスの予測器を改善するために、bounding box 回帰を適用します。そのため RPNは、各クラスの対応する確率でさまざまなサイズのバウンディングボックスを提供します。
残りのネットワークは Fast R-CNN に似ています。Faster R-CNNは Fast R-CNNより10倍高速であり、VOC-2007のようなデータセットの精度は同様です。
表2-5-5

Regressionベースの物体検出
これまでに説明したすべての手法では
・最初に物体候補が生成され
・次にこれらの候補を分類/回帰に送る
というパイプラインを構築することで分類問題として検出を行っています。
回帰問題として検出を行う方法はいくつかあり、最も人気のある2つはYOLOとSSDです。
これらの検出器は、シングルショット検出器とも呼ばれます。以下ではそれを見ていきます。
2-6. YOLO(You only Look Once)
YOLOは予め画像全体をグリッド分割しておき、各領域ごとに物体のクラスとbounding boxを求める、という方法を採用しています。
CNNのアーキテクチャがシンプルになったため、Faster R-CNNに識別精度は少し劣りますが45-155FPSの検出速度を達成しています。
またスライディングウィンドウや領域候補(Region Proposal)を使った手法と違い、1枚の画像の全ての範囲を学習時に利用するため、周辺のコンテクストも同時に学習することができます。
これにより、背景の誤検出を抑えることができるようになり、背景の誤検出はFast R-CNNの約半分の抑えることが出来ました。
YOLO 詳細
画像全体をS×Sのグリッドに分割し、各グリッドはN個の bounding box と confidence を予測します。confidence は、
- bounding box の精度と
- bounding box が実際にオブジェクトを含むかどうか(クラスに関係なく)
を反映します。YOLO はまた、トレーニング中の各クラスの各 bounding box の分類スコアを予測します。両方のクラスを組み合わせて、各クラスが予測される bounding box に存在する確率を計算することができます。
合計SxSxN 個の bounding box が予測されますが、多くの bounding box は confidence スコアが低く、しきい値を30%と設定すると、下の例に示すようにほとんどのものが削除されます。
図2-6

YOLOは超高速であり、リアルタイムで実行可能です。
- 従来手法では、生成された領域候補(region proposals)のみを見ていたのに対して、
- YOLOは画像全体を一度のみ見ることです。
したがって、背景の誤検出回避に役立ちます。
YOLOの欠点
- 分割されたグリッドサイズは固定かつ、グリッド内で識別できるクラスは1つ
- 検出できる物体の数は2つ
という制約があるため、 グリッド内に大量の物体がある場合に弱くなります。
2-7. SSD(Single Shot Detector)
SDは様々な階層の出力層からマルチスケールな検出枠を出力できるよう設計されています。
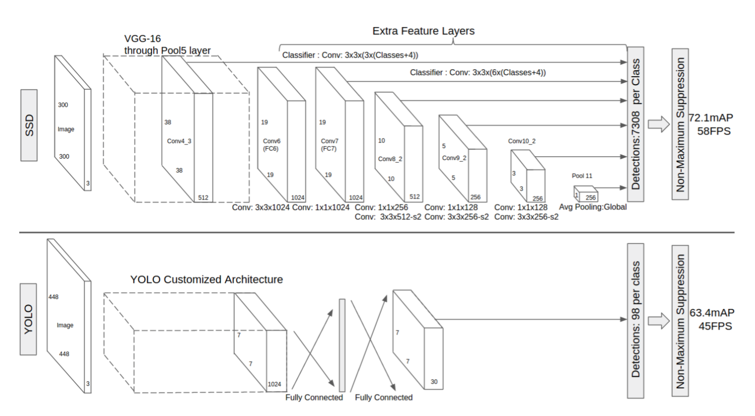
SSDの主な特徴
- YOLOより高速で、Faster R-CNNと同等の精度を実現
- 小さなフィルタサイズのCNNを特徴マップに適応することで、物体のカテゴリと位置を推定
- マルチスケール特徴マップ:様々なスケールの特徴を利用し、アスペクト比ごとに識別することで、高精度の検出率を達成
- 比較的低解像度でも高精度に検出できる
- end-to-end のトレーニングが可能
入力画像上で畳み込みネットワークを1回だけ実行し、特徴マップを計算します。特徴マップ上に小さな3×3サイズの畳み込みカーネルを実行して、bounding box と分類確率を予測します。
SSDはまた、Faster R-CNN に類似した様々なアスペクト比でアンカーボックスを使用し、ボックスを学習するのではなくオフセットを学習します。
図2-7-1

上図の様に異なる階層から特徴マップを使い、比較的小さなサイズの物体も検出可能なため、入力画像サイズを小さくしても、それなりの精度が出るため、高速化できています。
初期ボックスとアスペクト比
異なるアスペクト比に対応するために、アスペクト比ごとに出力を分けています。
k個のアスペクト比の異なるボックス、c個の物体クラスと、4つのオフセットを出力する場合、1つセルのサイズは(c+4)k になります。
特徴マップがm*nとすると、 最終的な出力マップは、(c+4)kmn になります。
閾値(0.5)を超えるJaccard係数でボックスを選択します。
Jaccard係数
集合と集合の類似度を計算します。テキストマイニングの分野では文章の類似度で用いられ、文章Aに使われている単語と文章Bに使われている単語を抜き出して、その単語の和集合と共通部分から値を求めます。物体検出の場合は領域重複の度合いを表す。
J(A,B)=∣A∩B∣∣A∪B∣ =∣A∩B∣|A|+|B|−∣A∩B∣J(A,B)=∣A∩B∣∣A∪B∣ =∣A∩B∣|A|+|B|−∣A∩B∣
ロス関数
ロス関数は
1. 物体の位置ずれである、localization loss (loc) と
2. 物体のクラスである、confidence loss (conf)
L(x,c,L,g)=1NLconf(x,c)+αLloc(x,l,g)L(x,c,L,g)=1NLconf(x,c)+αLloc(x,l,g)
を組み合わせたもの。各画像で出てきた全ての出力に対して、上式を計算する。(Nはマッチしたボックスの数、重みαは実験では1.0)
localization lossは予測されたボックス(l)と正解ボックス(g)のパラメータ間でのSmooth L1 loss です。Faster R-CNNと同様、初期 bounding box(d)の中心(cx, xy)とその幅(w)と高さ(h)についてオフセットを回帰予測します。
ここで、Smooth L1 loss は以下の通り。
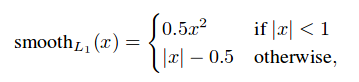

confidence loss は複数クラスの確信度(c)に対するソフトマックス誤差です。

初期ボックスのスケールとアスペクト比の選択
単一の予測ネットワーク中の異なる層から特徴マップを利用することで,すべての物体スケールについて同じパラメータを共有しながら,同様の効果を得ることが可能。
先行研究によると、以下が分かっています。
- 下位層が入力物体の詳細をより良く捉えているため,下位層からの特徴マップを使用することでどの区画に何があるのかの認識(semantic segmentation)の品質を向上できる
- 特徴マップからプールされた global context を加えることで分割結果をスムーズになる
1つのフレームワークの異なる階層からの特徴マップは異なる(経験的な)受容野サイズを持つことが知られていますが、論文中では特定の特徴マップがある特定のスケールの物体を担当するように学習するよう,初期ボックスの敷き詰めを設計しています。
m個の特徴マップを予測に使用するものとすると、各特徴マップについての初期ボックスのスケールは次のように計算されます。
sk=smin+smax−sminm−1(k−1),k∈[1,m]sk=smin+smax−sminm−1(k−1),k∈[1,m]
ここでsmin=0.2,smax=0.9smin=0.2,smax=0.9であり,最下位層は0.2,最上位層は0.9のスケールを持つこと意味します。その中間のすべての階層は等間隔に設定されます。
ハードネガティブマイニング(hard negative mining)
マッチング工程後、特に初期ボックスの数が大きい場合、多くの初期ボックスは負(negatives)になり、正と負の訓練例の間に大きな不均衡となります。
すべての負の訓練例を使わず、
- 各初期ボックスについて confidence loss でソートして
- 負と正の比率が最大でも3:1になるようにして選びます
これにより,より速い最適化とより安定した訓練に繋がると報告されています。
データ拡張
モデルを様々な入力物体サイズと形状に対してロバストにするために、各訓練画像は次に示すオプションによってランダムにサンプリングしています。
- 元の入力画像全体を使用
- 物体との最小の jaccard overlap が0.1, 0.3, 0.4, 0.7, 0.9となるように パッチをサンプリング
- ランダムにパッチをサンプルする.
各サンプルパッチのサイズは元の画像サイズの[0.1, 1]で,アスペクト比は1/2と2の間。サンプルパッチの中に正解ボックスの中心がある場合には,正解ボックスの重複部分は保持するものとします。前述のサンプリングステップの後に,各サンプルパッチは,フォトメトリックな歪みを適用することに加えて,固定サイズにリサイズされ,確率0.5で水平にフリップします。
速度と性能のトレードオフ
- 精度を優先する場合 Faster R-CNN
- 計算に制限がある場合 SSD
- 超高速を求める場合 YOLO
がオススメ。以下は速度と性能のトレードオフを視覚化したものです。
図2-7-2
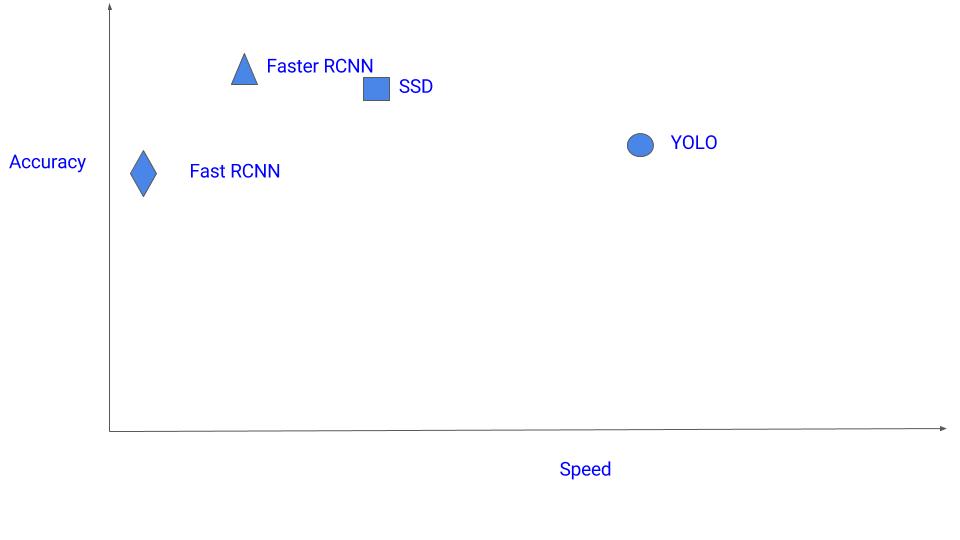
下図は SSD、YOLO、Faster R-CNN のパフォーマンス比較グラフです。
検出物体のサイズが大きい場合は、SSDはFaster R-CNN と同等の精度ですが、物体サイズが小さい場合は、Faster R-CNN の精度はSSDより良く差が大きい。
図2-7-3
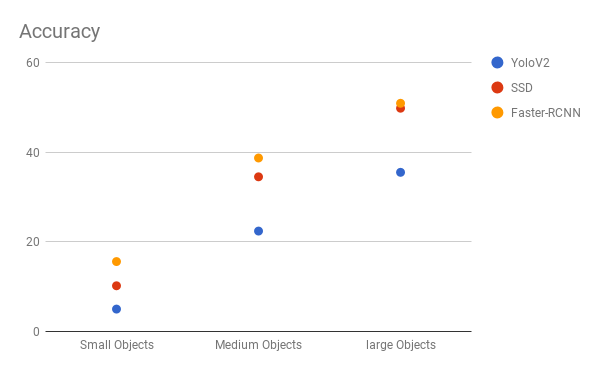
SSD のVOC2007のデータセットにおいての成績
- 300×300の画像サイズにおいて 74.3% mAPという高精度を保ったまま、59 FPSを達成(YOLOは63.4% mAP)
- 512×512の画像サイズにおいては、76.9% mAPを達成(Faster R-CNNは73.2% mAP)
2-8. Mask R-CNN
Facebook AIの研究結果。
Mask R-CNNでは、Faster R-CNNのCNN機能の上に全結合ネットワークが追加され、マスク(セグメント化出力)が生成されます。
図2-8-1
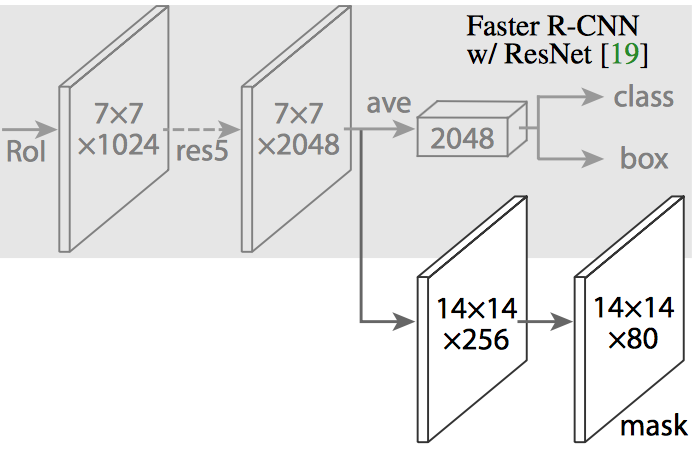
Mask R-CNNは、Faster R-CNN に分岐(上記の画像の白い部分)を追加し、指定ピクセルが物体の一部かどうかを示すバイナリマスクを出力します。
追加されたブランチ部は、CNNベースの特徴マップの上にある完全畳み込みネットワークです。
ブランチ部の入力と出力
- 入力:CNN特徴マップ
- 出力:物体なら1, 物体でないなら 0 を表すバイナリマスク、を持つ行列
このパイプラインを期待どおりに動作させるために、小さな調整を行う必要がありました。
RoiAlign :RoIPoolの再配置
図2-8-2

図2-4−4 のように、関心領域のサイズは、プールセクションの数によって完全に割り切れず、RoIPoolによって選択された特徴マップの領域が元の画像の領域からわずかにずれていました。
画像のセグメンテーションは、bounding box とは異なり、ピクセルレベルで特定する必要があるため、当然不正確でした。なので、元の画像の領域により正確に対応するように、RoIPoolの代わりに、RoIAlignを通過させます。
図2-8-3

プールセクションのずれによる丸め誤差が発生していたRoIPoolの代わりに、RoIAlignでは、このような丸め誤差を双線形補間(biliear interpolation)([12])を使用して避けています。補間処理した各セクションの値からMaxプーリングを行います。
これにより高いレベルで、RoIPoolによって引き起こされる不整合を避けることができます。これらのマスクが生成されると、Mask R-CNNはそれらをFaster R-CNNの分類および bounding box と組み合わせて、そのようなきわめて正確なセグメンテーションを生成します。
バイリニア補間
各セル内の4点の近傍4ピクセルからバイリニア補間(双線形補間,bilinear interpolation)を用いて各点の値を計算します。
図2-8-4
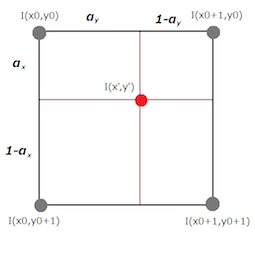
- 周囲4セルの値を取得し、(I(x0,y0),I(x0+1,y0),I(x0,y0+1),I(x0+1,y0+1))
- 補正後のセルの中央点 (x',y')からの距離を求めます。
- 距離によって重み付け(0~1)を行います。(距離が小さいほど重みは大きい)
- 1.の値の加重平均をセルの中央点における値 I(x',y') とします。
以下の式で求められます。
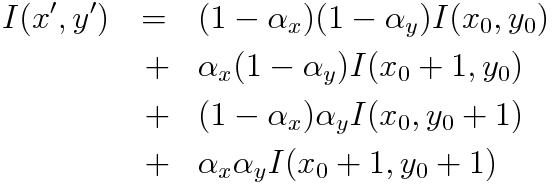
まとめ
物体検出手法の選択は非常に重要であり、解決しようとしている問題と環境で異なります。
物体検出は、自動運転車、セキュリティおよび監視、および多くの産業アプリケーションなど、コンピュータビジョンの多くの実際的なアプリケーションのバックボーンです。
参考文献
[1] Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
https://arxiv.org/abs/1406.4729
[2] SSD: Single Shot MultiBox Detector
https://arxiv.org/abs/1512.02325.
[3] R-CNN
https://arxiv.org/abs/1311.2524
[4] Fast R-CNN
https://arxiv.org/abs/1504.08083
[5] Faster R-CNN
https://arxiv.org/abs/1506.01497
[6] Mask R-CNN
https://arxiv.org/abs/1703.06870
[7] Zero to Hero: Guide to Object Detection using Deep Learning: Faster R-CNN,YOLO,SSD
http://cv-tricks.com/object-detection/faster-r-cnn-yolo-ssd/
[8] A Brief History of CNNs in Image Segmentation: From R-CNN to Mask R-CNN
https://blog.athelas.com/a-brief-history-of-cnns-in-image-segmentation-from-r-cnn-to-mask-r-cnn-34ea83205de4
[9] Mask R-CNN
https://www.slideshare.net/windmdk/mask-rcnn
[10] Region of interest pooling explained
https://blog.deepsense.ai/region-of-interest-pooling-explained/
[11] Instance segmentation with Mask R-CNN
https://lmb.informatik.uni-freiburg.de/lectures/seminar_brox/seminar_ss17/maskrcnn_slides.pdf
[12] 線形補間、バイリニア補間
https://goo.gl/snAcXQ