元記事は下記です:
https://deepmind.com/blog/neural-scene-representation-and-rendering/
[日本語]
DeepMindのAIは、一つの画像から全体の風景を再作成できました
最近、画像レンダリングの開発は驚異的です。ちょうど昨年、Nvidiaのニューラル・ネットワーク研究は、写真に雪や雨を加えるなどの写真的な操作を生成することができました。ニューラルネットワークは今まで非常に限定された形態のAIでありましたが、強い予測能力を開発することができています。先週、Googleの子会社であるDeepMindは、ニューラルネットワークが単一の画像からシーンのさまざまな視点を作成できることを発表しました。
画像の1つの視点にある色んな物体のサイズとシェーディングのデーターを入力すると、このAIは完全な3Dレンダリングを吐き出して、関連するオブジェクトの場所を予測や推定ができます。以前の研究では、ニューラルネットワークは、物体または様々な深度にラベルを有する風景の画像を必要としていました。通常の場合は人間のプログラマが数百万の画像にラベル付けるのを必要となります。しかし、DeepMindはこの方法を回避することができ、Generative Query Network(GNQ)と呼ばれる方法でニューラルネットワークを訓練しました。
GQNモデルは2つのネットワークで構成されています:表現ネットワークと生成ネットワークです。表現ネットワークは、ある視点から風景を予測するよりも、シーンおよび生成ネットワークの様々な視点を与えられます。表現ネットワークは風景のイメージをどんどん蓄積するので、生成ネットワークのオブジェクト・アイデンティティ、位置、色および領域レイアウトなどのすべての情報を生成します。
GQNモデルは本質的に、受信したピクセルからこの情報を抽出する方法自体を学習しています。このデータの収集では、典型的な空の色や特定のオブジェクトの対称性などの統計パターンを記録します。統計的パターン認識を可能にすることによって、シーンのより抽象的な詳細のための能力の一部を開きます。
DeepMindの研究者は、「幼児や動物のように、GQNは周囲の世界の観測を理解することによって学ぶ」と述べています。GQNは、観察されず予測できない新しいシーンを本質的に想像しやオブジェクトが他の側から見えるようになりました。空間的な関係を理解することで、仮想ロボットの腕を制御し、ボールを移動させたり、自己修正することができます。
このモデルはコンピュータ生成の風景でしか訓練されていないため、このモデルにはまだ限界があります。 DeepMindは、このテクニックを実際のシーンや写真にまで拡大できることを期待しています。この種の場面理解は、空間的および時間的な質問の物理学的研究ならびに仮想的で拡張された現実の開発に多大な貢献をするかもしれません。
好奇心を持っている人のために、彼らの実験で使用されたデータセットはGithubを介して公開されています:https://github.com/deepmind/gqn-datasets
[English]
DeepMind's AI Can Recreate Entire Landscapes From Single Pictures
The breakthroughs in image rendering recently has been extraordinary. Just last year, Nvidia's neural network research was able to generate photorealistic manipulations such as adding snow or rain to photographs. Although neural networks are still a very limited form of AI, it has proven to develop effective predictive capabilities. Last week Google's subsidiary, DeepMind, has published that their neural networks are able to create various viewpoints of a scene just from a single image.
When fed an image of a single vantage point that contains objects of various sizes and shading, their AI can spit out a full 3D rendering making predictions and estimations on where related objects should stand in the picture. In previous iterations of this research, neural networks were needed pictures of scenes to have labels for objects or various depths. These required millions of images usually each hand labeled by human programmers. But DeepMind has able to circumvent this method and has trained their neural network in a method called the Generative Query Network (GNQ).
The GQN model is made up of two networks; a representation network and a generation network. The representation network is fed various perspectives of a scene and the generative network than predicts the scene from a queried perspective. As the representation network accumulates more and more images of a scene, it produces all information such as object identities, positions, colors and area layout for the generative network.
GQN model is essentially learning by itself how to extract this information from the pixels it receives. With this collection of data, it notes any statistical patterns such as typical colors of the sky or symmetries of certain objects. By allowing for statistical pattern recognition, it opens some of it capacity for more abstract details of a scene.
DeepMind's researcher describes, "Much like infants and animals, the GQN learns by trying to make sense of its observations of the world around it." The GQN has is essentially able to 'imagine' new scenes that have not been observed and able to predict what objects would look like from the other side. The understanding of spatial relationships allow it to control a virtual robot arm and move a ball around and even self-correct.
There are still limitations to this model as it has only been trained in computer generated scenery. DeepMind hopes to be able to expand upon this technique to real life scenes or photographs. This sort of scene understanding may contribute much to physics research in space and time querying as well as in virtual and augmented reality development.
For those who are curious, the datasets used in their experiments are publically available via Github: https://github.com/deepmind/gqn-datasets
2018年10月18日木曜日
「インターネット」で勝てなかった日本が、「深層学習」で勝つには 東大・松尾豊氏
NVIDIAは2018年9月13、14日に「GTC Japan 2018」を開催した。本稿では、東京大学の松尾豊氏の講演「人工知能をビジネスに実装するとき、今やるべきこと」の内容を要約してお伝えする。
あらためて学ぶ、深層学習の原理とは

東京大学 特任准教授、日本ディープラーニング協会 理事長の松尾豊氏
東京大学 特任准教授で、日本ディープラーニング協会理事長の松尾豊氏は、深層学習をビジネスで活用する際、「深層学習がどのような仕組みなのか理解しないと、深層学習を利用したビジネスを前に進めるのは難しい」と述べ、深層学習の原理を「深い関数を利用した最小二乗法だ」と説明する。
最小二乗法は、統計学で用いられる「回帰分析」などにおいて、係数を推定する方法だ。「例えばMicrosoft Excelでは、xを気温、yを冷たい飲料の売り上げとしたときの散布図に近似直線(y=ax+b)を引ける。近似直線を引くための位置(係数a,b)を決定付けるアプローチが、最小二乗法だ」
松尾氏は、「深層学習とは、最小二乗法の巨大なお化けのようなものだ」と紹介し、画像の各画素xから「猫(y=1)」か「猫でないか(y=0)」を出力する猫関数を例として取り上げた。「100x100の画像で猫関数を作成する場合は、1万個もの変数が必要になる。深層学習の場合は、中間的な関数を介して、これを3層、4層と深くする。こうすることで、少ないパラメーターで表現力を高め、効率的に学習できる」


この深さが重要な理由については、料理に例えて説明する。「料理の素材が一層だとして、1回しか手を加えない場合は、単純な料理しかできない。しかし、複数の階層で手を加えることができれば、料理にバリエーションが生まれる。深層学習にも同じことがいえる」

深層学習の階層構造を料理に例えた
深層学習の原理を説明した松尾氏は、深層学習をビジネスに活用しようとする際には、「散布図のように、xとyを定義する必要がある」と考察する。
「最近、『人工知能で政治を』という話を耳にしたが、『xとyが定義できますか』と問いたい。xとyが定義できなければ、データを集めてもプロジェクトはうまくいかない。画像をxとしてyを犬や猫にすれば画像認識、xを英語の文としてyを日本語の文とすれば翻訳、というように、xとyを何にするかを考えるべきだ」

xとyを簡単に定義できるものほど「深層学習で成果を上げやすい」という
松尾氏が現在注目する2つの研究
2012年、Googleが深層学習を用いた猫画像認識に関する論文を発表してから、6年間で深層学習に関する研究が「急激に進んだ」と松尾氏は振り返る。2018年現在は、画像認識におけるエラー率は3%台で、「人間のスコアを大きく上回り、画像認識による物体検出ができやすい環境になった」と深層学習の現状を分析する。
「深層学習の精度向上で、画像認識や、映像からの行動認識を実現することが可能になった。一方、人間が脳で無意識に行う運動や行動のための予測は実現できていない」
松尾氏によれば、2018年現在、深層学習を用いて現実世界を理解、予測できるような手法はないという。しかし、「研究が進めば、深層学習が現実世界を理解、予測できるようになるのではないか」と予測し、その実現に向けた研究として「World Models」や「Generative Query Network(GQN)」に注目しているそうだ。
World Modelsは、外界から受け取った運動や行動などの刺激を基に、将来の外界世界の構造をシミュレートするという研究だ。GQNは、複数の視点における画像のペアを基に、別の視点の画像を生成する。この2つの研究が発展することで、「ボールを投げればどうなるか、土を掘ればどうなるか、といった現実空間の情報を、深層学習で予測できるようになる」と松尾氏は考察する。
「深層学習は汎用目的技術(GPT)の仲間入りを果たす」
「現在、ロボットと深層学習を組み合わせた事例が増えている」と言う松尾氏は、その事例の一つとしてAI(人工知能)を研究する非営利団体「OpenAI」の腕型ロボット「Dactyl」を紹介した。
Dactylは、指が動く速度やキューブの重さなど、さまざまなパラメーターをランダム化したシミュレーター環境において、強化学習アルゴリズムを用いた学習でモデルを生成する。その結果、人間のような指の動きを実現させているという。松尾氏は、こうした事例を「眼を持った機械の登場」と表現する。
加えて、2018年3月にMicrosoftが中国語から英語への翻訳精度を人間と変わらないレベルにまで高めたという記事や、特定の人物の表情や目の動きを深層学習で再現する「Deep Video Portraits」を取り上げ、深層学習の研究の発展について予測する。
「深層学習とロボットが融合し、『眼を持った機械』が登場してきている。今後は、深層学習による翻訳が実用レベルに達する可能性も出てきた。日本の労働市場が、現在の欧州と米国のような環境になれば、単純な事務職からクリエイティブな職業までも深層学習が使われる時代がやってくる」
松尾氏はこの予測を基に、「深層学習が人類の汎用目的技術(GPT)の一つになる」と考察する。汎用目的技術とは、インターネットやトランジスタ、車軸の発明といった、社会全体に影響を及ぼした技術のことだ。
松尾氏は「現在の企業の時価総額ランキング上位企業には、『インターネット』を利用したビジネスを展開した企業が多い。20年後、『深層学習』が汎用目的技術の一つになっていれば、『深層学習事業』を展開する企業がランキング上位に入っていてもおかしくない」と予想。講演最後には、ものづくりに強い日本企業に対する思いを述べて講演を終えた。

世界の時価総額上位企業ランキング
「日本はインターネットというGPTには不向きだった。しかし、深層学習においては『機械を持った眼』のように、ものづくりと深層学習を組み合わせることで、日本のものづくりの強みを生かせられる。今から20年後に深層学習がどうなっているのか、先を読んで考えたプレイヤーが勝つので、深層学習を学ぶと同時に、深層学習が社会をどう変えるのか、死ぬほど考え抜いていってほしい」
GitHubが「GitHub Actions」を発表、開発者が好きな機能を使ってワークフローを自動化
GitHubは2018年10月16日(米国時間)、米サンフランシスコで開催中のGitHub Universeで、ソフトウェア開発者のワークフローを自動化する機能「GitHub Actions」を発表した。
開発者のためのワークフロー自動化については、CI/CD(Continuous Integration/Continuous Delivery)関連を含め、さまざまなツールやサービスが存在する。だが、こうしたツールやサービスを使ったとしても、前工程や後工程で、別のツールを組み合わせて使う面倒が発生することが多い。また、統合的なツールでは、一部の機能が個々の開発者のニーズに合わないケースもある。さらに、自身のためのワークフローを自ら作り上げたいこともある。
これらのニーズに応え、「workflow as code」を実現する機能として、GitHubが1年をかけて開発したのが「GitHub Actions」。発表当日に、限定的なβ提供が始まった。
GitHub Actionsでは、ビジュアルエディターあるいはスクリプトで「アクション」をつなげ、フローを構築する。数百ステップに及ぶフローを構築することも可能という。アクションの実体はDockerコンテナ。発表時点でGitHubは450のアクション提供している。他の開発者によるアクションを使うこともできるし、自身で開発してもよい。
GitHub Universeの基調講演では、Dockerイメージのビルド、テストを経て、Heroku、Google Cloud Platform、Microsoft Azure、Amazon Web Servicesなどのコンテナサービスに対し、同時にコードをデプロイするまでの一連の流れを自動化するデモを見せた。
つまり、例えばCI/CDに関して、GitHubは自前のツールを押し付けることはしないのだという。個々のソフトウェア開発者あるいは組織が、自らに適したツール/機能を組み合わせて使う自由とコントロールを与えるのが、GitHub Actionsの目的だとしている。
他の用途としては、特定のソフトウェア開発者によるPull Requestを行ったソフトウェア開発者の情報から、この開発者に紐づいたレビューワーを指定して自動的にリマインドを送る、GitHub.com上のコードをフィルターして自動的に取り込むなど、想像力次第で多様なGitHubおよび外部のサービス/機能を結び付けられるという。
開発者のためのワークフロー自動化については、CI/CD(Continuous Integration/Continuous Delivery)関連を含め、さまざまなツールやサービスが存在する。だが、こうしたツールやサービスを使ったとしても、前工程や後工程で、別のツールを組み合わせて使う面倒が発生することが多い。また、統合的なツールでは、一部の機能が個々の開発者のニーズに合わないケースもある。さらに、自身のためのワークフローを自ら作り上げたいこともある。
これらのニーズに応え、「workflow as code」を実現する機能として、GitHubが1年をかけて開発したのが「GitHub Actions」。発表当日に、限定的なβ提供が始まった。
GitHub Actionsでは、ビジュアルエディターあるいはスクリプトで「アクション」をつなげ、フローを構築する。数百ステップに及ぶフローを構築することも可能という。アクションの実体はDockerコンテナ。発表時点でGitHubは450のアクション提供している。他の開発者によるアクションを使うこともできるし、自身で開発してもよい。
GitHub Universeの基調講演では、Dockerイメージのビルド、テストを経て、Heroku、Google Cloud Platform、Microsoft Azure、Amazon Web Servicesなどのコンテナサービスに対し、同時にコードをデプロイするまでの一連の流れを自動化するデモを見せた。
つまり、例えばCI/CDに関して、GitHubは自前のツールを押し付けることはしないのだという。個々のソフトウェア開発者あるいは組織が、自らに適したツール/機能を組み合わせて使う自由とコントロールを与えるのが、GitHub Actionsの目的だとしている。
他の用途としては、特定のソフトウェア開発者によるPull Requestを行ったソフトウェア開発者の情報から、この開発者に紐づいたレビューワーを指定して自動的にリマインドを送る、GitHub.com上のコードをフィルターして自動的に取り込むなど、想像力次第で多様なGitHubおよび外部のサービス/機能を結び付けられるという。
データ分析をクラウドでやれば、コストは4分の1に——みずほ銀行が「BigQuery」を試して分かったこと
昨今、FinTechなどを背景に金融業界でのデータ活用が進んでいるが、同時にデータ分析の難度も大きく高まっている。WebのアクセスログやSNSでの行動など、テクノロジーの進化によって収集、分析すべきデータは増え続けており、施策の構築までも含め、膨大な工数を取られるケースも少なくない。
素早く有効な施策を打ちたいのに、分析に時間がかかり過ぎてしまう——メガバンクのみずほ銀行もそんな悩みを抱えていた。データの抽出からクレンジング、加工と、分析したいデータが増えれば増えるほど、その"前準備"にかかる時間も増えていくためだ。同社は、オンプレミス環境に1000人規模の社員が利用するDWH(Teradata)があるものの、データ加工などに向くツールではなく、データの増加に対応し切れなくなってきたのだという。
「機能の拡張性や外部データとの連携などの視点で考えれば、データの加工や分析については、クラウド上で行うのが理想的だといえます」
こう話すのは、同社の個人マーケティング推進部の山泉亘さんだ。大手複合機メーカーでクラウド化を進めてきた経験を生かし、2018年にみずほ銀行に転職。みずほ銀行でもクラウド活用を進める活動を行っている。
データ分析基盤をパブリッククラウドへと移行することを検討している中で、GoogleのBigQueryに注目し、IT部門とPoCを共同企画。Googleに相談したところ、ちょうどBigQueryが東京リージョンで使えるようになるタイミングだったため、アルファユーザーとして参加したという。PoCを実施したのは2018年の3月のこと。社内システムからGoogle Cloud Storageにデータを手動コピーする形で行い、3つの項目を検証した。
検証の結果、BigQuery周りについては「現状使っているTeradataと同等の性能」が得られ、Cloud Dataprepについては、データ処理方法のレコメンドなどの支援機能が有用であり、ユーザー部門自らがデータ準備ができることを確かめられたという。しかし、PoCの中でいくつか反省すべき点があったと山泉さんは話す。
「単純なデータのロードについては、8000万レコード(約20GB)で10秒強、ETLとの連携部分での読み込みは1億レコード(約30GB)で1分強という結果が出ました。われわれはその結果で満足してしまったのですが、Googleから『もっとデータを投げないんですか?』と聞かれて初めて、テストだからと遠慮していたことに気付かされたのです」(山泉さん)
オートスケーリング機能があるため、「データ処理が多重になっても、パフォーマンスが低下しにくいというメリットがある」と山泉さん。扱うデータ量が少なければ、このメリットは実感しにくいが、今後データ量や分析者が増えるのならば強い味方になる。BigQueryを使うことでデータ分析にかかるコストは、現行の4分の1程度にまで削減できると試算しているそうだ。
「オンプレミスのデータ分析基盤では、計算リソースの上限に合わせた働き方になるが、クラウドであれば、計算リソースの上限から解放されて業務を集約、並列化できるようになります。空いた時間を分析の企画や計画など、より上流工程に充てることができるようになるはず。働き方改革にもつながるでしょう」(山泉さん)
今後、みずほ銀行がBigQueryを実導入するかどうかは未定ではあるものの、クラウド活用に向けた体制作りをさらに進めていくという。
「クラウド活用には、情報開発子会社や外部ベンダーなどの"構築組織"、IT部門など案件全体を管理する"PM(プロジェクトマネジメント)組織"、そしてクラウドの経験を通じて、ビジネスの拡大を目指す"ユーザー組織"という三者の連携が欠かせません。これらの優秀なリソースを集約し、継続的な改善が続けられる環境を作る。今後はそういった『クラウドCoE(Center of Excellence)』を構築できればと考えています」
素早く有効な施策を打ちたいのに、分析に時間がかかり過ぎてしまう——メガバンクのみずほ銀行もそんな悩みを抱えていた。データの抽出からクレンジング、加工と、分析したいデータが増えれば増えるほど、その"前準備"にかかる時間も増えていくためだ。同社は、オンプレミス環境に1000人規模の社員が利用するDWH(Teradata)があるものの、データ加工などに向くツールではなく、データの増加に対応し切れなくなってきたのだという。
「機能の拡張性や外部データとの連携などの視点で考えれば、データの加工や分析については、クラウド上で行うのが理想的だといえます」
こう話すのは、同社の個人マーケティング推進部の山泉亘さんだ。大手複合機メーカーでクラウド化を進めてきた経験を生かし、2018年にみずほ銀行に転職。みずほ銀行でもクラウド活用を進める活動を行っている。
データ分析基盤をパブリッククラウドへと移行することを検討している中で、GoogleのBigQueryに注目し、IT部門とPoCを共同企画。Googleに相談したところ、ちょうどBigQueryが東京リージョンで使えるようになるタイミングだったため、アルファユーザーとして参加したという。PoCを実施したのは2018年の3月のこと。社内システムからGoogle Cloud Storageにデータを手動コピーする形で行い、3つの項目を検証した。
検証の結果、BigQuery周りについては「現状使っているTeradataと同等の性能」が得られ、Cloud Dataprepについては、データ処理方法のレコメンドなどの支援機能が有用であり、ユーザー部門自らがデータ準備ができることを確かめられたという。しかし、PoCの中でいくつか反省すべき点があったと山泉さんは話す。
「単純なデータのロードについては、8000万レコード(約20GB)で10秒強、ETLとの連携部分での読み込みは1億レコード(約30GB)で1分強という結果が出ました。われわれはその結果で満足してしまったのですが、Googleから『もっとデータを投げないんですか?』と聞かれて初めて、テストだからと遠慮していたことに気付かされたのです」(山泉さん)
オートスケーリング機能があるため、「データ処理が多重になっても、パフォーマンスが低下しにくいというメリットがある」と山泉さん。扱うデータ量が少なければ、このメリットは実感しにくいが、今後データ量や分析者が増えるのならば強い味方になる。BigQueryを使うことでデータ分析にかかるコストは、現行の4分の1程度にまで削減できると試算しているそうだ。
「オンプレミスのデータ分析基盤では、計算リソースの上限に合わせた働き方になるが、クラウドであれば、計算リソースの上限から解放されて業務を集約、並列化できるようになります。空いた時間を分析の企画や計画など、より上流工程に充てることができるようになるはず。働き方改革にもつながるでしょう」(山泉さん)
今後、みずほ銀行がBigQueryを実導入するかどうかは未定ではあるものの、クラウド活用に向けた体制作りをさらに進めていくという。
「クラウド活用には、情報開発子会社や外部ベンダーなどの"構築組織"、IT部門など案件全体を管理する"PM(プロジェクトマネジメント)組織"、そしてクラウドの経験を通じて、ビジネスの拡大を目指す"ユーザー組織"という三者の連携が欠かせません。これらの優秀なリソースを集約し、継続的な改善が続けられる環境を作る。今後はそういった『クラウドCoE(Center of Excellence)』を構築できればと考えています」
名刺サイズ「カードケータイ」をドコモが発表、画面は電子ペーパーを採用
ドコモが4Gケータイとして世界最薄・最軽量をうたう「カードケータイ」を発表しました。価格は実質1万円(税込)で、月々サポートを除いた価格は3万1752円でした。11月下旬発売予定。
「カードケータイは」、薄さ5.3mm・重さ47gという、携帯電話としては異次元のコンパクトさが特徴。実機に触ってみると、厚みはそこそこあるものの、縦横の大きさは名刺とほぼ同じで、ポケットやカードケース、手帳などにもすっと収まります。
ディスプレイはE-Inkで、2.8インチの600 x 480解像度。タッチ入力に対応するものの、E-Inkのため応答速度は液晶などに大きく劣ります。フロントライトは非搭載のため、暗闇では光源が別途必要です。
機能的にも妥協はありません。高音質な通話が楽しめる「VoLTE」に対応するほか、「SMS」や「Wi-Fiテザリング」、「WEBブラウジング」にも対応。また、フリック入力にも対応し、SMSやWEBブラウジング中にもサクッと文字入力できます。連続通話時間は2時間です。
特筆すべきはその価格でしょうか。税込実質1万円で、フィーチャーフォンと同じ料金プランが利用可能。メインスマホとは別の、サブケータイとしての需要は大きそうです。
開発は京セラが担当。ドコモの製品担当者は「VoLTE対応でどれだけ薄く軽くできるかのチャレンジだった」と語り「(ストラップホールを備えるため)首からぶらさげて持ち歩いているが、業務用の電話、通話に関しては何不自由なく使えている」とコメントしました。
「カードケータイは」、薄さ5.3mm・重さ47gという、携帯電話としては異次元のコンパクトさが特徴。実機に触ってみると、厚みはそこそこあるものの、縦横の大きさは名刺とほぼ同じで、ポケットやカードケース、手帳などにもすっと収まります。
ディスプレイはE-Inkで、2.8インチの600 x 480解像度。タッチ入力に対応するものの、E-Inkのため応答速度は液晶などに大きく劣ります。フロントライトは非搭載のため、暗闇では光源が別途必要です。
機能的にも妥協はありません。高音質な通話が楽しめる「VoLTE」に対応するほか、「SMS」や「Wi-Fiテザリング」、「WEBブラウジング」にも対応。また、フリック入力にも対応し、SMSやWEBブラウジング中にもサクッと文字入力できます。連続通話時間は2時間です。
特筆すべきはその価格でしょうか。税込実質1万円で、フィーチャーフォンと同じ料金プランが利用可能。メインスマホとは別の、サブケータイとしての需要は大きそうです。
開発は京セラが担当。ドコモの製品担当者は「VoLTE対応でどれだけ薄く軽くできるかのチャレンジだった」と語り「(ストラップホールを備えるため)首からぶらさげて持ち歩いているが、業務用の電話、通話に関しては何不自由なく使えている」とコメントしました。
2018年10月17日水曜日
while, forループのelse
Pythonではwhile, forのループにelseを使えます。
これは他の言語には珍しい機能で、ありがちなケースでは「ループ処理で何かを探索して見つけたらbreakする、breakしなかったら見つからなかった」といったケースでフラグ変数を使う必要がなくなります。
elseを使わないループ
elseを使わない、ありがちなループ探索処理の場合は、見つかった場合にフラグを更新してbreakし、ループの外側でフラグの状態をチェックしたif文を記述します。
ary = [1, 3, 9, 2, 1]
exist = False
for n in ary:
if n == 9:
exist = True
break
if exist:
print "Found! 9"
else:
print "Not found 9.."
elseを使うループ
elseを使った場合は、existフラグを使用する必要がなくなります。
ary = [1, 3, 9, 2, 1]
for n in ary:
if n == 9:
print "Found! 9"
break
else:
print "Not found 9.."
elseブロックが処理されるのは、「breakでループを抜けなかった時」です。補足すると「ループを一度も実行しなかった時」も含まれます。
たとえば以下のケースは、aryが長さ0のリストなのでループ内は一度も処理しません。したがってelseブロックが実行されます。
ary = []
for n in ary:
if n == 9:
print "Found! 9"
break
else:
print "Not found 9.."
これは他の言語には珍しい機能で、ありがちなケースでは「ループ処理で何かを探索して見つけたらbreakする、breakしなかったら見つからなかった」といったケースでフラグ変数を使う必要がなくなります。
elseを使わないループ
elseを使わない、ありがちなループ探索処理の場合は、見つかった場合にフラグを更新してbreakし、ループの外側でフラグの状態をチェックしたif文を記述します。
ary = [1, 3, 9, 2, 1]
exist = False
for n in ary:
if n == 9:
exist = True
break
if exist:
print "Found! 9"
else:
print "Not found 9.."
elseを使うループ
elseを使った場合は、existフラグを使用する必要がなくなります。
ary = [1, 3, 9, 2, 1]
for n in ary:
if n == 9:
print "Found! 9"
break
else:
print "Not found 9.."
elseブロックが処理されるのは、「breakでループを抜けなかった時」です。補足すると「ループを一度も実行しなかった時」も含まれます。
たとえば以下のケースは、aryが長さ0のリストなのでループ内は一度も処理しません。したがってelseブロックが実行されます。
ary = []
for n in ary:
if n == 9:
print "Found! 9"
break
else:
print "Not found 9.."
ペッパー、英議会デビュー=人間以外で初めて発言
ソフトバンクの人型ロボット「ペッパー」が16日、英下院教育委員会の参考人質疑に招かれ、意見陳述した。世界の議会制度の模範となった英議会の長い歴史上、人間以外が発言するのは初めてという。
質疑のテーマは、ロボットなどの新しい技術を活用する第4次産業革命と人工知能(AI)がもたらす教育の発展。ペッパーは他の研究者らとともに出席した。
委員会の冒頭で自己紹介を求められ、「おはようございます。委員長、このような機会をいただき、ありがとうございます」と礼儀正しくあいさつ。ペッパーを活用した英ミドルセックス大学での教育活動について滑らかな英語で説明し、議場から拍手が起きた。
投稿サイト、ツイッターではペッパーの英議会デビューをめぐり、「素晴らしい」と歓迎する意見があった半面、「ただの人形芝居だ」と批判的な声も上がった。「ロボットのような(定型的な発言を繰り返すばかりの)メイ首相が同胞に道を切り開いた」と、現政権を皮肉る投稿もあった。
質疑のテーマは、ロボットなどの新しい技術を活用する第4次産業革命と人工知能(AI)がもたらす教育の発展。ペッパーは他の研究者らとともに出席した。
委員会の冒頭で自己紹介を求められ、「おはようございます。委員長、このような機会をいただき、ありがとうございます」と礼儀正しくあいさつ。ペッパーを活用した英ミドルセックス大学での教育活動について滑らかな英語で説明し、議場から拍手が起きた。
投稿サイト、ツイッターではペッパーの英議会デビューをめぐり、「素晴らしい」と歓迎する意見があった半面、「ただの人形芝居だ」と批判的な声も上がった。「ロボットのような(定型的な発言を繰り返すばかりの)メイ首相が同胞に道を切り開いた」と、現政権を皮肉る投稿もあった。
近未来コンビニ、支払いはゲートくぐるだけ
家電見本市「CEATEC(シーテック)ジャパン2018」が千葉市の幕張メッセで16日に開幕するのを前に、ローソンは15日、コンビニエンスストアの将来像を示す展示を報道陣に公開した。人口減に伴う人手不足を背景に、革新的なITを活用して店舗運営の効率化と省人化の実現を目指す内容だ。
ローソンはシーテックに小売業として初出展した。「平成37年のコンビニ」をテーマに、あらゆるモノがネットにつながる「IoT」などさまざまな技術を盛り込んだ"ハイテク"コンビニの姿を示した。
目玉展示の「ウォークスルー決済」は、利用客が商品を手にしたままゲートをくぐるだけで支払いが済むシステム。商品一つ一つに取り付けた「RFID」と呼ぶ電子タグの情報をゲート側のセンサーで読み取り、どの商品がどれだけ売れたかを把握する。現金の受け渡しが不要で、レジの無人化が可能となる。
RFIDの活用でリアルタイムで在庫管理や消費期限の把握もできる利点があり、ローソンはコストもにらみながら37年までに導入を急ぐ考えだ。
このほか、店員の代わりとして、映像の店員「バーチャルクルー」も公開。人工知能(AI)を搭載した仮想の店員が、利用客の購入履歴を基にその人に合わせたおすすめ商品を紹介などする。成長著しいアマゾンなどネット通販勢の販売手法をコンビニも採り入れる狙いだ。
YouTubeで接続障害 「アクセスできない」報告相次ぐ
「YouTubeにアクセスできない」──10月17日午前10時ごろから、ネット上でこんな報告が相次いでいる。ITmedia NEWS編集部で確認したところ、PCとスマートフォンのいずれからもYouTubeにアクセスできない状況だ。
PCのWebブラウザでYouTubeにアクセスすると「500 Internal Server Error」と表示され、スマートフォンアプリ(Android)では「エラーが発生しました」と表示された。YouTube側のサーバに何らかの障害が発生していると思われる。
Twitterでは全世界で「#YouTubeDOWN」がトレンド入りしている。多くの国で同様の障害が発生しているようだ。
午前11時40分、YouTubeにアクセスできることを確認した。障害は解消したとみられる。
PCのWebブラウザでYouTubeにアクセスすると「500 Internal Server Error」と表示され、スマートフォンアプリ(Android)では「エラーが発生しました」と表示された。YouTube側のサーバに何らかの障害が発生していると思われる。
Twitterでは全世界で「#YouTubeDOWN」がトレンド入りしている。多くの国で同様の障害が発生しているようだ。
午前11時40分、YouTubeにアクセスできることを確認した。障害は解消したとみられる。
マイナス値のfloor,trunc,ceil,roundとキャストの違い
浮動値を整数値に丸める時に利用できる関数は、floor,trunc,round,ceilやキャストが思いつくと思いますが、何も考えずに利用すると負数が入った場合に思わぬバグの要因となります。
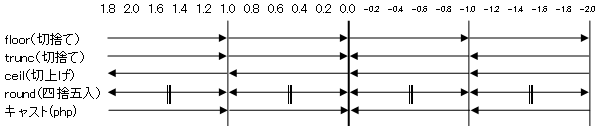
floorは語句の通り常に下さい値の方へ向かい、それ以外は0に近づくように動くと考えればいいでしょう。キャストはSQLでは違う結果となります。
| floor(-1.8) | -2 |
| trunc(-1.8) | -1 |
| ceil(-1.8) | -1 |
| round(-1.5) | -2 |
| (int)(-1.8) | -1 |
truncは実装されていない言語系もあります(php)のでその場合はキャストを利用できるかもしれません。
利用には実際の処理系で確認して下さい。
2018年10月15日月曜日
NVIDIA、大規模データ分析や機械学習向けGPUアクセラレーションプラットフォーム「RAPIDS」を公開
NVIDIAは2018年10月10日(現地時間)、ドイツで開催された「GPU Technology Conference Europe 2018」において、データサイエンスや機械学習向けのオープンソースソフトウェア(OSS)のGPUアクセラレーションプラットフォーム「RAPIDS」を公開した。
RAPIDSは、GPUアクセラレーションを用いるアナリティクスや機械学習向けに一連のOSSソースライブラリを提供するもの。今後はデータ可視化もサポートするという。NVIDIAのエンジニアと主要なOSSコントリビューターがこの2年間、密接に協力して開発してきた成果だ。
RAPIDSにより、企業は高速に膨大なデータを分析し、ビジネスに関する的確な予測を行えるという。データサイエンティストは、クレジットカード詐欺の予想や小売り在庫の予測、顧客の購入行動の理解など、複雑なビジネス課題への取り組みにおいて、パフォーマンスを高めることができるとした。
既にさまざまな業種の先進的なIT活用企業が、NVIDIAのGPUアクセラレーションプラットフォームとRAPIDSのアーリーアダプターとなっているという。さらに世界の主要なIT企業が、新しいシステム、データサイエンスプラットフォーム、ソフトウェアソリューションを通じてRAPIDSをサポートしている。その中にはHewlett Packard Enterprise(HPE)、IBM、Oracle、Cisco Systems、Dell EMC、Lenovo、NERSC、NetApp、Pure Storage、SAP、SAS Instituteなどが含まれる。データアナリティクスにおけるGPUの重要性に関するコンセンサスが広がりつつあることを反映したものだという。
機械学習を50倍に加速すると主張
NVIDIAは、アナリストの推計として、データサイエンスや機械学習向けのサーバ市場規模を年間200億ドル、科学的解析やディープラーニングと合わせたハイパフォーマンスコンピューティング(HPC)の市場規模を約360億ドルと説明している。
NVIDIAの創業者兼CEOのジェンスン・フアン氏は、次のように述べている。
「データアナリティクスと機械学習は、これまでHPC市場でアクセラレーションの対象となっていなかった最大の分野だ。だが、今後は世界の巨大産業で、機械学習で作成されたアルゴリズムが膨大なサーバで実行され、市場や環境の複雑なパターンを検知して、そこからはじき出される迅速かつ正確な予測が収益に直接影響するようになる」
「GPUアクセラレーションプラットフォームであるRAPIDSは、GPU向け並列処理ライブラリ群『CUDA』とそのグローバルエコシステムをベースに、OSSコミュニティーとの密接な協力によって生み出された。最も一般的なデータサイエンスライブラリとワークフローとのシームレスな統合により、RAPIDSは機械学習をスピードアップする。われわれはこれまでディープラーニングで行ってきたように、機械学習を加速させていく」
RAPIDSは、データサイエンティストがGPUでデータ分析パイプライン全体を実行する際に必要なツールを初めて提供するという。
RAPIDSの初期ベンチマークでは、「NVIDIA DGX-2」システムで機械学習アルゴリズム「XGBoost」を用いてトレーニングを行い、CPUのみのシステムと比べて50倍の速度を記録した。データサイエンティストは、データセットのサイズによって一般に数時間から数日間かかっていたトレーニング時間を、数分間から数時間に短縮できることになる。
OSSコミュニティーとの連携をうたう
RAPIDSは、「Apache Arrow」「pandas」「scikit-learn」といった一般的なOSSプロジェクトをベースに、最も一般的なPythonのデータ分析ツールチェーンにGPUアクセラレーションを加えることで実現したもの。

RAPIDSがうたうGPUを用いたデータサイエンスの加速(出典:RAPIDS)
NVIDIAはRAPIDSへ機械学習ライブラリや機能を追加するために、「naconda」「BlazingDB」「Databricks」「Quansight」「scikit-learn」といったOSSエコシステムのコントリビューターの他、Ursa Labsの代表で、Apache Arrowとpandas、さらには急速に拡充が進むPythonのデータサイエンスライブラリを生んだウェス・マッキニー氏の協力を得ている。
「GPUアクセラレーションに基づいたデータサイエンスプラットフォームであるRAPIDSは、Apache Arrowで強化された次世代コンピュテーショナルエコシステムだ。NVIDIAとUrsa Labsの協力により、コアとなるArrowライブラリのイノベーションが加速し、アナリティクスと機能エンジニアリングワークロードのパフォーマンスに大きな飛躍をもたらすだろう」(マッキニー氏)
RAPIDSのOSSライブラリスイートは、専用サイトからすぐに利用できる。コードはApacheライセンスで公開されている。RAPIDSのコンテナバージョンは、「NVIDIA GPU Cloud」のコンテナレジストリで2018年10月8日週から提供を開始する予定だ。
ブラウン大学の研究チーム、錯視を起こすニューラルモデルを構築
米ブラウン大学は2018年9月21日(米国時間)、同大学のコンピュータビジョン研究チームによる目の錯覚(錯視)に関する研究成果を発表した。
この研究は、"文脈効果"(context-dependent optical illusion)に起因するタイプの錯視について、神経メカニズムを解明することを目的に行われた。
文脈効果とは、空間的または時間的に前後となる刺激の影響によって、ある(視覚)刺激の知覚の内容が変化してしまう現象。
研究者は次のように述べている。「錯視は、『バグではなく機能』だというコンセンサスができつつある。錯視はわれわれの視覚系のエッジケースかもしれないが、われわれの視覚は、日常生活における物体の識別に関しては非常に強力だ」

研究で用いた文脈依存型の錯視の例 中央の例では外周円の色が文脈となって、内周の円の色知覚が引きずられてしまう。右側の例では輝度の高い円が周囲の円の色知覚に影響を及ぼす(出典:Serre Lab/Brown University)
研究チームはまず、大脳視覚野の解剖学データと神経生理学データに基づいた計算モデルを作成した。このモデルを作成した目的は、複雑な刺激(例えば文脈効果による錯視を引き起こす画像)を受けたときに、近隣の皮質ニューロン(神経細胞)がどのように相互にメッセージを送信し、お互いの反応を調整するのかを明らかにすることだ。
ディープラーニングのアルゴリズムを改善できる可能性
研究チームはこのモデルにイノベーションを1つ盛り込んだ。特定パターンのフィードバック結合(水平結合)を、ニューロン間に設けたことだ。このフィードバック結合は、視覚的文脈に応じて中央ニューロンの反応を増減(促進または抑制)できる。
ほとんどのディープラーニングアルゴリズムは、レイヤー間のフィードフォワード結合しか含んでおらず、レイヤー内のニューロン間のフィードバック結合という要素は見られない。
モデルの作成後、研究チームは、文脈効果によってさまざまな錯視を引き起こす画像をモデルに入力した。さらに、促進的、抑制的フィードバック結合の強度を"チューニング"した。モデルのニューロンが、視覚野の神経生理学データと同様に反応するようにするためだ。
文脈効果によるさまざまな錯視画像でモデルを繰り返しテストした結果、モデルが人間のように錯視することを確認した。
「われわれのモデルは、文脈効果による錯視に関して、視覚野の働きを説明するのに必要十分なシンプルなものになっている。われわれは、神経生理学データを説明できるモデルからスタートし、人間の心理物理学データを予測することが可能になった」と研究者は述べている。
研究チームはこのモデルを基に、錯視のメカニズムの統一的な説明を提供するだけでなく、人工視覚の進化にも貢献したいと考えている。
研究者によると、最新の人工視覚アルゴリズム(顔のタグ付けや、停止標識の認識などに使われている)は、文脈の把握に苦戦している。研究チームは、文脈による錯視に基づいてチューニングされた水平結合を取り入れることで、この弱点に対処できると考えている。
登録:
投稿 (Atom)