How to explain gradient boosting
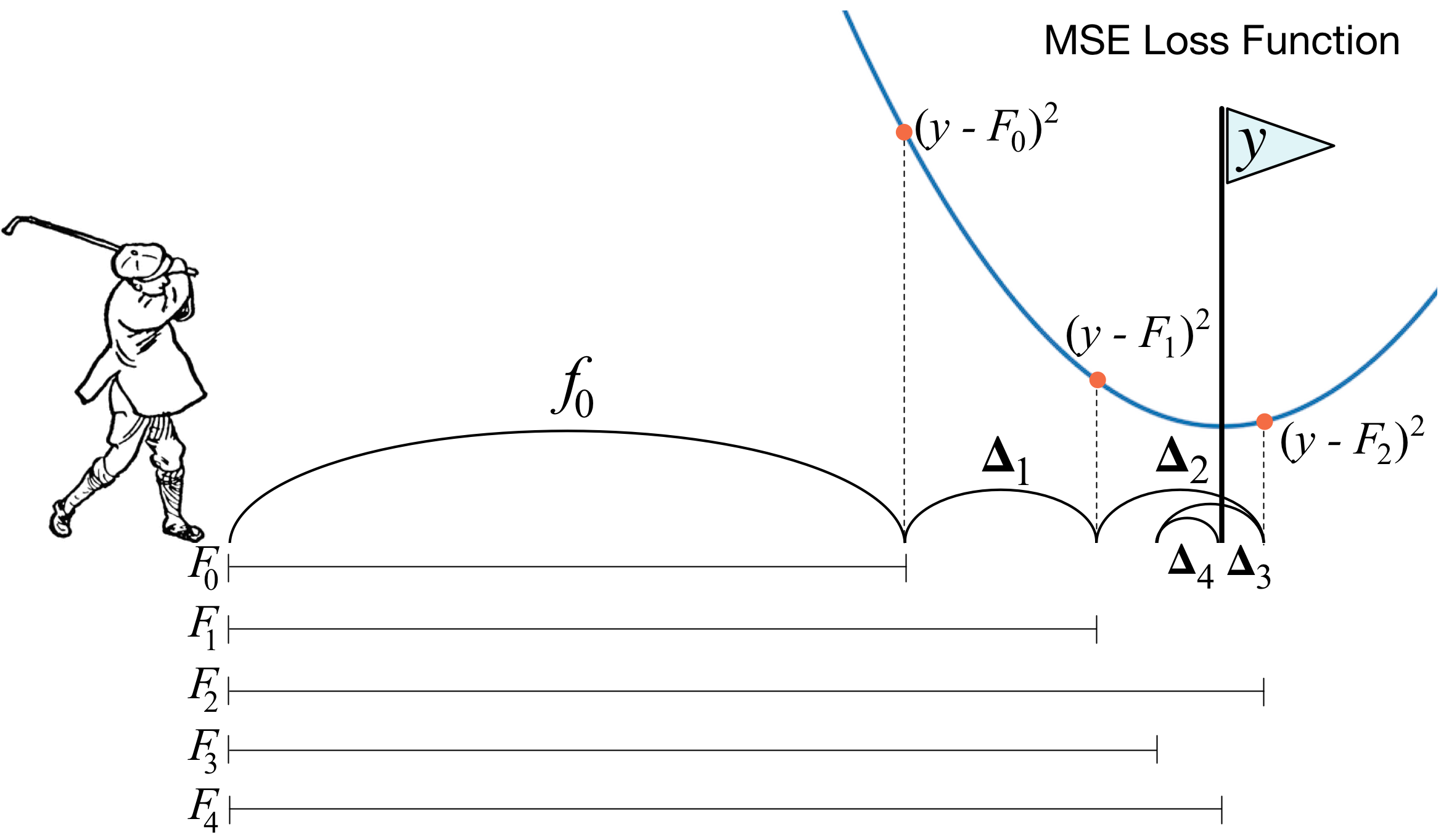
Gradient boosting machines (GBMs) are currently very popular and so it's a good idea for machine learning practitioners to understand how GBMs work. The problem is that understanding all of the mathematical machinery is tricky and, unfortunately, these details are needed to tune the hyper-parameters. (Tuning the hyper-parameters is required to get a decent GBM model unlike, say, Random Forests.) Our goal in this article is to explain the intuition behind gradient boosting, provide visualizations for model construction, explain the mathematics as simply as possible, and answer thorny questions such as why GBM is performing "gradient descent in function space."
The Matrix Calculus You Need For Deep Learning
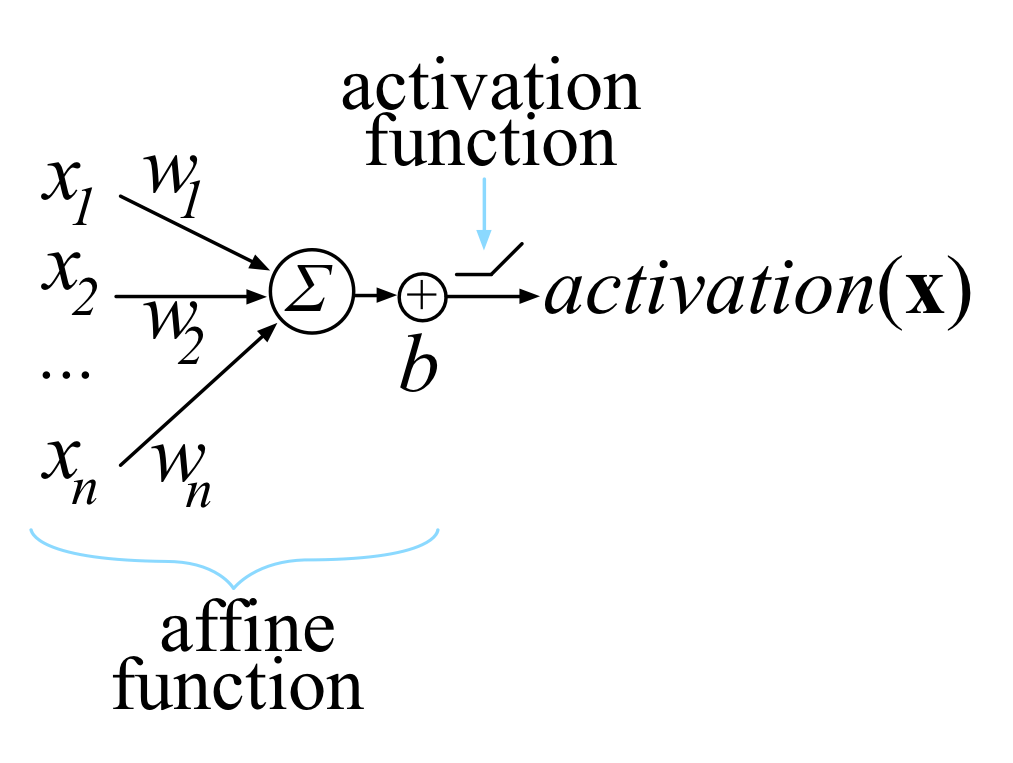
This article explains all of the matrix calculus you need in order to understand the training of deep neural networks. Most of us last saw calculus in school, but derivatives are a critical part of machine learning, particularly deep neural networks, which are trained by optimizing a loss function. Pick up a machine learning paper or the documentation of a library such as PyTorch and calculus comes screeching back into your life like distant relatives around the holidays. And it's not just any old scalar calculus that pops up--you need differential matrix calculus, the shotgun wedding of linear algebra and multivariate calculus. (printable PDF at arxiv.org)
Beware Default Random Forest Importances
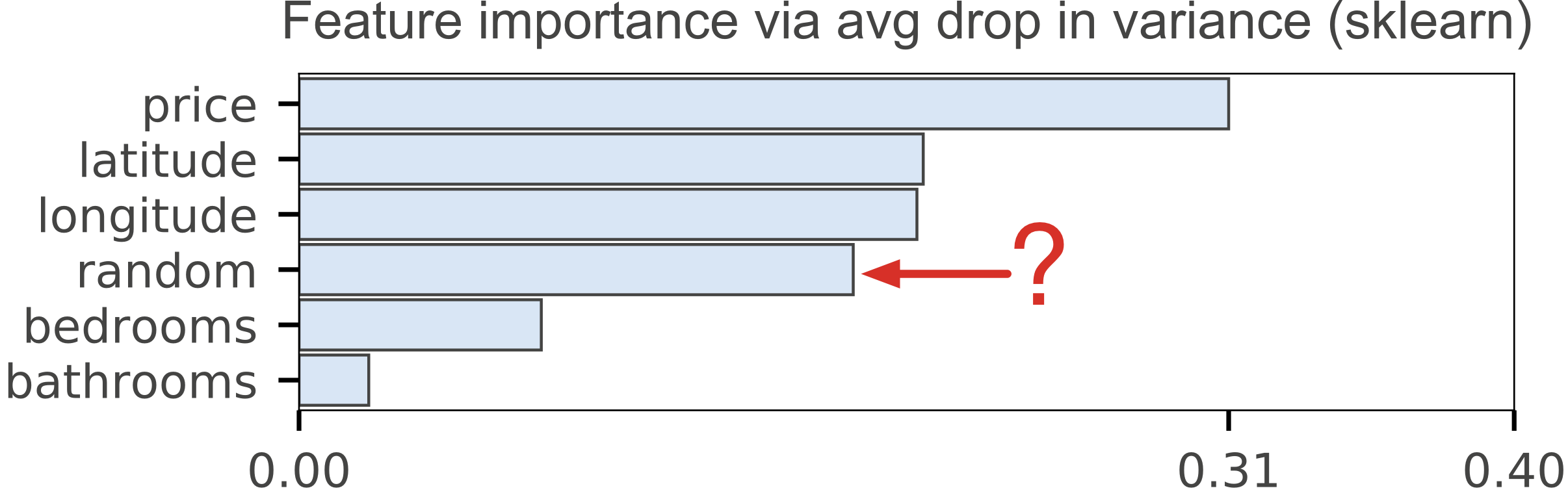
Training a model that accurately predicts outcomes is great, but most of the time you don't just need predictions, you want to be able to interpret your model. The problem is that the scikit-learn Random Forest feature importance and R's default Random Forest feature importance strategies are biased.
Books
The Mechanics of Machine Learning
Terence Parr and Jeremy HowardThis book is a primer on machine learning for programmers trying to get up to speed quickly. You'll learn how machine learning works and how to apply it in practice. We focus on just a few powerful models (algorithms) that are extremely effective on real problems, rather than presenting a broad survey of machine learning algorithms as many books do. Co-author Jeremy used these few models to become the #1 competitor for two consecutive years at Kaggle.com. This narrow approach leaves lots of room to cover the models, training, and testing in detail, with intuitive descriptions and full code implementations.
This is a book in progress; first two chapters posted.
Libraries
rfpimp

The scikit-learn Random Forest feature importance and R's default Random Forest feature importance strategies are biased. To get reliable results in Python, use permutation importance, provided here and in our rfpimp package (via pip).
lolviz

A simple Python data-structure visualization tool that started out as a List Of Lists (lol) visualizer but now handles arbitrary object graphs, including function call stacks! lolviz tries to look out for and format nicely common data structures such as lists, dictionaries, linked lists, and binary trees. This package is primarily for use in teaching and presentations with Jupyter notebooks, but could also be used for debugging data structures, such as decision trees or graphs.
0 件のコメント:
コメントを投稿