R-CNNについて
R-CNNについては公式の論文を読むことをオススメします。
この場では説明しません(~_~;)
Non-Maximum Suppressionについて
論文に登場
Non-Maximum Suprressionは、R-CNNの公式の論文にこう記されています。
Given all scored regions in an image, we apply a greedy non-maximum suppression (for each class independently) that rejects a region if it has an intersection-over-union (IoU) overlap with a higher scoring selected region larger than a learned threshold.
画像の全ての候補領域に得点が付けられている場合、ある領域に、より高い得点で選択され、学習された閾値より大きな値を持つ領域とのIoU値が重複した場合、その領域を排除するnon-maximum suppressionを(各々クラスに対して独立して)適用する。
下手くそな翻訳ですが、直訳すると上のような意味になります。
Non-Maximum Suppressionとは何なのか
一言で説明すると、Non-Maximum Suppressionとは、同じクラスとして認識された重なっている状態の領域を抑制するためのアルゴリズムです。
以下で画像を交えながら説明します。
例えば、スティーブ・ジョブズの顔をR-CNNで検出しようと考えます。(余談ですが彼は私が最も尊敬する人物です。)

良い笑顔です(笑
R-CNNでは以下の手順で検出を行います。
- Selective Searchを用いて候補領域を切り出す。
- ニューラルネットワークを用いて、候補領域から特徴ベクトルを抽出する。
- サポートベクトルマシン(通称:SVM)を用いて、特徴ベクトルから顔かどうか判断する。
- Non-Maximum Suppressionを用いて、重複している領域を抑制する。
このプロセスを経て、最終的な顔の検出を行います。
本来は4番のNon-Maximum Suppressionの処理まで行うのですが、以下の画像では3番まで処理を行った結果を示しています。

Non-Maximum Suppressionを適用しない場合、同じ顔が複数検出されてしまいす。これではダメですよね。
上手くやって1つとして検出したいところです。
これができるのが Non-Maximum Suppression なのです!
Non-Maximum Suppressionを適用すると、以下の画像のように顔を1つとして検出することができます。

これが望んでいる結果ですよね。
アルゴリズムについて
Non-Maximum Suppressionを説明する前に説明しなければいけないことがあります。
それは、IoU値です。
IoUとは、Intersection over Unionの略です。
"百聞は一見にしかず"ということわざがある通り、以下の画像を見ていただければ一発で理解できると思います。
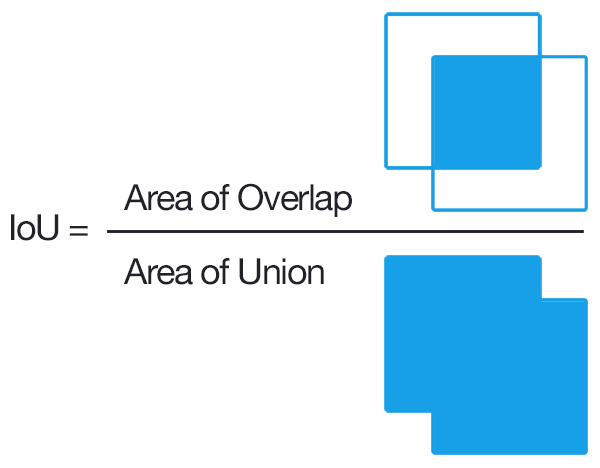
IoU値とは、画像の重なりの割合を表す値です。
IoU値が大きいほど、画像が重なっている状態ということになります。
IoU値が小さいほど、画像が重なっていない状態ということになります。
IoU値=0のとき、画像は全く重なっていない状態ということになります。
IoU値=0.5のとき、画像は半分重なっている状態ということになります。
IoU値=1.0のとき、画像は完全に重なっている状態ということになります。
さて、本テーマであるNon-Maximum Suppressionの話に戻ります。
重複している領域は、上で説明したIoU値を用いて行います。
例えば、右下の領域を基準として、IoU値の閾値を0.3とします。
右下の領域と他の2枚の領域のIoU値は、閾値よりも大きいのは明らかですよね?(重なりが多いことを意味しています。)
なので、他の2枚の領域は抑制(suppression)します。
すると、以下のようになります。
見事、領域が1つになりました!!
これこそが望む結果です!!
逆に、IoU値が閾値よりも低い領域は抑制せずに残しておくというわけです。
話をまとめます。
Non-Maximum Suppressionというのは難しいことをしているわけではありません。
ただ単に、重なりの大きい領域を抑制(削除)しているだけにすぎません。
抑制のためにIoU値という領域の重複具合を示す値を用いています。
IoU値が大きければ、領域の重なりが大きいとみなして一方の領域を抑制(削除)します。
逆に、IoU値が小さければ、領域の重なりが小さいとみなして両方の領域をそのままにしておきます。
ただ、これだけのことです。
このアルゴリズムを使うと何が良いのか?
最後に、このアルゴリズムの何が良いのかを考えてみましょう。
そのために、考えてもらいたいことがあります。
逆に、Non-Maximum Suppressionを使わないとすると、どのようにして領域を絞れば良いでしょうか?
パッと考えて思いつくのは、以下の画像の青枠のように、重なっている全ての領域を囲うことです。

(とりあえず、赤枠も残していますが、本番では消します。)
これならNon-Maximum Suprressionを使わなくても済むだろうと思ったあなた、甘いです!!w
これだと上手くいかない場合があるのです。
上手くいかない場合とは、以下のような場合です。
例えば、丁度よく2台の自動車が検出されたとします。

上の自動車2台を、ただ単純に囲うとどうなるでしょうか?

あら!?2台が1台として検出されてしまいましたね。
そうです、これではダメなんです。
ただ単純に囲うだけだと、2つ以上の同じ物体が近くにあると1つの物体として検出されてしまうのです。
なぜこうなってしまうのかというと、領域の重複具合を考慮していないからです。
そのためにNon-Maximum Suppressionでは、IoU値という数値を用いています。
Non-Maximum Suppressionを適用した場合、どうなるでしょうか?
当然、上手くいきます!
それぞれの領域とのIoU値は、閾値(例えば0.3)よりも明らかに小さいからです。
そういう場合は、抑制されないのでしたね。
以上がNon-Maximum Suppressionです。
サンプルのソースコード
Non-Maximum SuppressionのサンプルコードはこちらのブログにPythonで書かれたものが紹介されていました。
ぜひ、参考にしてみてください!
0 件のコメント:
コメントを投稿